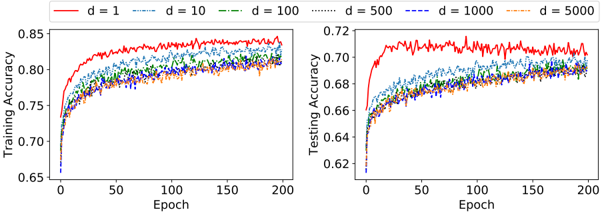
## Line Charts: Training and Testing Accuracy vs. Epoch for Different 'd' Values
### Overview
The image displays two side-by-side line charts comparing the training and testing accuracy of a model over 200 training epochs. The performance is plotted for six different values of a parameter labeled 'd' (d=1, 10, 100, 500, 1000, 5000). The charts share a common legend and x-axis but have separate y-axes for training and testing accuracy.
### Components/Axes
* **Legend:** Positioned at the top center, spanning both charts. It defines six line styles/colors:
* `d = 1`: Solid red line
* `d = 10`: Dashed blue line (lighter blue)
* `d = 100`: Dash-dot green line
* `d = 500`: Dotted black line
* `d = 1000`: Dashed blue line (darker blue, different dash pattern from d=10)
* `d = 5000`: Dash-dot orange line
* **Left Chart - Training Accuracy:**
* **Y-axis:** Label is "Training Accuracy". Scale ranges from 0.65 to 0.85, with major ticks at 0.05 intervals (0.65, 0.70, 0.75, 0.80, 0.85).
* **X-axis:** Label is "Epoch". Scale ranges from 0 to 200, with major ticks at 50-epoch intervals (0, 50, 100, 150, 200).
* **Right Chart - Testing Accuracy:**
* **Y-axis:** Label is "Testing Accuracy". Scale ranges from 0.62 to 0.72, with major ticks at 0.02 intervals (0.62, 0.64, 0.66, 0.68, 0.70, 0.72).
* **X-axis:** Label is "Epoch". Identical scale and ticks to the left chart.
### Detailed Analysis
**Training Accuracy (Left Chart):**
* **General Trend:** All six lines show a rapid increase in accuracy from epoch 0 to approximately epoch 25-50, after which they plateau with minor fluctuations.
* **Performance Hierarchy:** The line for `d=1` (red) consistently achieves the highest training accuracy, plateauing near ~0.84-0.85. The lines for `d=10`, `d=100`, `d=500`, and `d=1000` cluster together, plateauing in the range of ~0.81-0.83. The line for `d=5000` (orange) appears to plateau at the lowest level among the group, approximately ~0.80-0.81.
* **Noise/Variance:** The `d=1` line exhibits the most visible high-frequency noise or variance during its plateau phase. The other lines appear slightly smoother.
**Testing Accuracy (Right Chart):**
* **General Trend:** Similar to training, all lines show a steep initial rise, followed by a plateau. The overall accuracy values are lower than their training counterparts.
* **Performance Hierarchy:** The `d=1` (red) line again achieves the highest accuracy, plateauing around ~0.71-0.72. The remaining lines (`d=10` through `d=5000`) form a tighter cluster, plateauing between approximately ~0.68 and ~0.70.
* **Noise/Variance:** The `d=1` line shows significantly more pronounced noise and larger downward spikes during its plateau compared to its training curve and the other testing curves. The other lines are relatively smoother and more tightly grouped.
### Key Observations
1. **Consistent Superiority of d=1:** The model with `d=1` achieves the highest accuracy on both training and testing datasets.
2. **Generalization Gap:** For all 'd' values, there is a clear gap between training accuracy (~0.80-0.85) and testing accuracy (~0.68-0.72), indicating some degree of overfitting.
3. **Increased Variance with d=1:** The `d=1` model exhibits the most unstable performance (highest variance) during the plateau phase, especially in testing accuracy.
4. **Diminishing Returns/Plateau for High 'd':** Models with `d=100`, `d=500`, `d=1000`, and `d=5000` show very similar performance to each other, particularly in testing, suggesting that increasing 'd' beyond 100 yields minimal change in final accuracy.
5. **Potential Overfitting with d=1:** While `d=1` has the highest test score, its high variance and the notable gap from its training score might suggest it is more prone to overfitting or is less stable than models with higher 'd' values.
### Interpretation
The charts demonstrate the impact of the parameter 'd' on model learning dynamics and generalization. A lower 'd' value (`d=1`) leads to higher peak accuracy but at the cost of increased model variance and instability, as seen in the noisy testing curve. This could imply that `d=1` represents a model with higher capacity or less regularization, allowing it to fit the training data more closely but making it more sensitive to fluctuations in the test set.
Conversely, higher 'd' values (100 and above) result in slightly lower but much more stable and consistent performance across both training and testing. The clustering of these lines suggests a regime where increasing 'd' further has a negligible effect, possibly indicating that the model's capacity or the problem's complexity is saturated at that point.
The persistent gap between training and testing accuracy for all models is a classic sign of overfitting. The task for a practitioner would be to determine if the higher accuracy of `d=1` is worth its instability, or if the more robust performance of a model like `d=100` is preferable for deployment. The parameter 'd' likely controls a key aspect of model architecture or regularization strength.