\n
## Screenshot: Reinforcement Learning Environment
### Overview
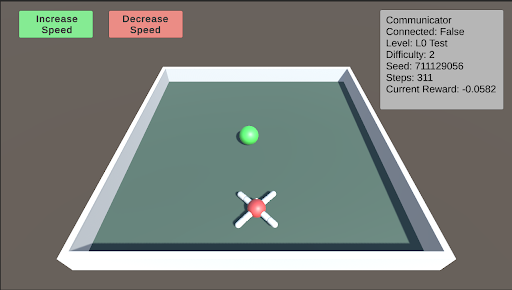
The image depicts a screenshot of a reinforcement learning environment. It shows a simulated arena with a red agent (likely a robot) and a green ball. The environment includes controls for adjusting the simulation speed and a status panel displaying various parameters. There is no chart or graph, but rather a visual representation of a state within a simulation.
### Components/Axes
The screenshot contains the following elements:
* **Arena:** A trapezoidal, grey-walled enclosure.
* **Agent:** A red, spherical object with four white appendages extending outwards, positioned near the bottom center of the arena.
* **Ball:** A green, spherical object positioned above the agent.
* **"Increase Speed" Button:** A green rectangular button in the top-left corner.
* **"Decrease Speed" Button:** A red rectangular button next to the "Increase Speed" button.
* **Status Panel:** A grey rectangular panel in the top-right corner displaying simulation parameters.
### Content Details
The Status Panel displays the following information:
* **Communicator:** Connected: False
* **Level:** L0 Test
* **Difficulty:** 2
* **Seed:** 711129056
* **Steps:** 311
* **Current Reward:** -0.0582
### Key Observations
The "Communicator" is disconnected. The simulation is at Level 0 with a difficulty of 2. The simulation has run for 311 steps, and the current reward is a negative value (-0.0582), suggesting the agent is not performing optimally. The seed value (711129056) indicates a specific initialization of the simulation.
### Interpretation
This screenshot represents a snapshot of a reinforcement learning agent attempting to interact with its environment. The negative reward suggests the agent is currently failing to achieve its goal (likely to reach or interact with the green ball). The disconnected communicator might indicate a lack of external control or monitoring. The low level and difficulty suggest this is an early stage of training. The seed value allows for reproducibility of the simulation. The visual setup suggests a task involving navigation and potentially manipulation of the ball by the agent. The agent's design with appendages could indicate it has some form of locomotion or manipulation capabilities. The overall setup is a common paradigm for testing and developing reinforcement learning algorithms.