## Bar Chart: Percentage of problems where Meta-Tuning improves performance at each level: GPT-4 vs Gemini
### Overview
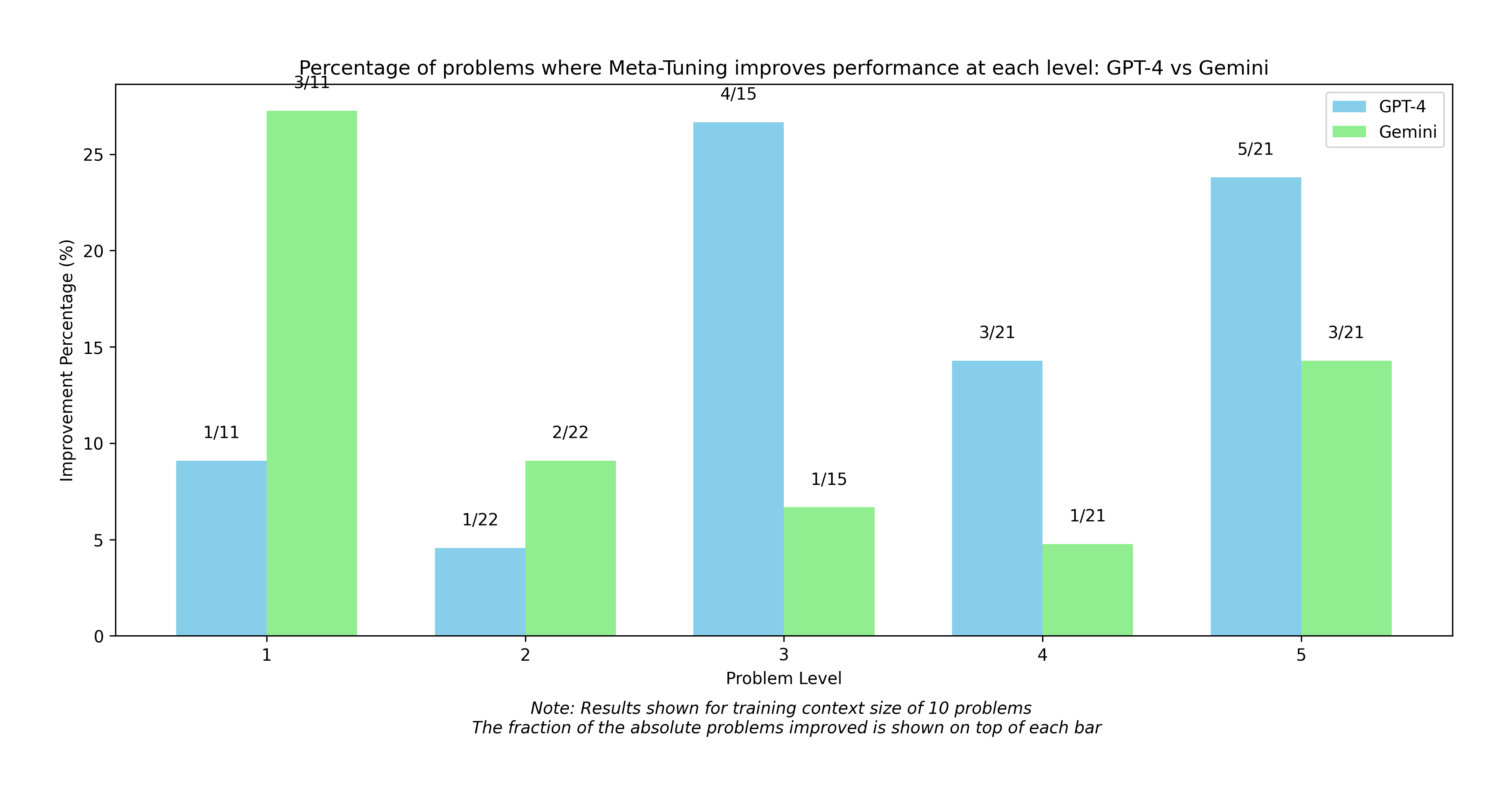
The chart compares the percentage improvement in problem-solving performance between GPT-4 and Gemini across five problem levels (1-5) when using Meta-Tuning. Results are based on a training context size of 10 problems, with fractions indicating the number of improved problems out of total tested.
### Components/Axes
- **X-axis**: Problem Level (1-5)
- **Y-axis**: Improvement Percentage (%)
- **Legend**:
- Blue = GPT-4
- Green = Gemini
- **Title**: "Percentage of problems where Meta-Tuning improves performance at each level: GPT-4 vs Gemini"
- **Note**: "Results shown for training context size of 10 problems. The fraction of the absolute problems improved is shown on top of each bar."
### Detailed Analysis
| Problem Level | GPT-4 (Blue) | Gemini (Green) |
|---------------|--------------|----------------|
| 1 | 9% (1/11) | 28% (3/11) |
| 2 | 4% (1/22) | 9% (2/22) |
| 3 | 27% (4/15) | 7% (1/15) |
| 4 | 14% (3/21) | 5% (1/21) |
| 5 | 24% (5/21) | 14% (3/21) |
### Key Observations
1. **Level 1**: Gemini dominates with 28% improvement vs GPT-4's 9%.
2. **Level 2**: Both models show minimal improvement (4% vs 9%), with Gemini slightly ahead.
3. **Level 3**: GPT-4 outperforms Gemini (27% vs 7%), with the largest performance gap.
4. **Level 4**: GPT-4 maintains advantage (14% vs 5%), though improvement is modest.
5. **Level 5**: GPT-4 leads again (24% vs 14%), but the gap narrows compared to Level 3.
### Interpretation
The data reveals a nuanced relationship between model performance and problem complexity:
- **Gemini excels in foundational problems** (Levels 1-2), suggesting stronger baseline reasoning capabilities.
- **GPT-4 dominates complex problems** (Levels 3-5), indicating superior handling of advanced reasoning tasks.
- **Level 4 anomaly**: GPT-4's 14% improvement (3/21) vs Gemini's 5% (1/21) suggests Meta-Tuning particularly benefits GPT-4 in mid-complexity problems.
- **Training context impact**: The consistent 10-problem training context across levels implies that problem difficulty, rather than training data volume, drives performance differences.
The fractions reveal interesting patterns: GPT-4 shows higher absolute improvement in Levels 3 and 5 despite similar training contexts, while Gemini's fractional improvements decrease more sharply with problem complexity. This suggests Meta-Tuning may amplify GPT-4's strengths in complex problem-solving more effectively than it does for Gemini.