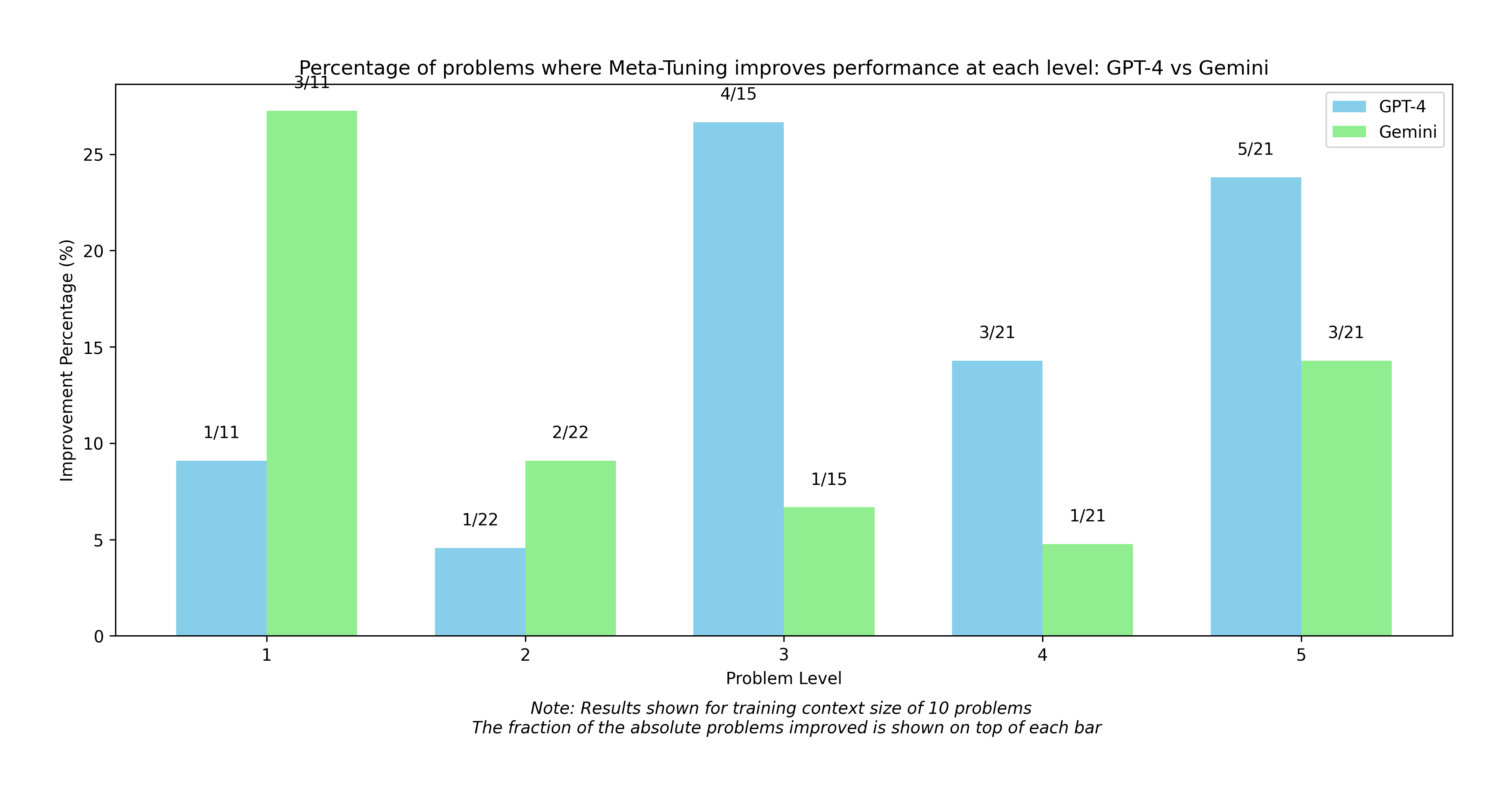
## Bar Chart: Meta-Tuning Performance Improvement (GPT-4 vs Gemini)
### Overview
The image is a bar chart comparing the percentage of problems where Meta-Tuning improves performance for GPT-4 and Gemini at different problem levels (1 to 5). The chart displays the improvement percentage on the y-axis and the problem level on the x-axis. Each problem level has two bars, one for GPT-4 (sky blue) and one for Gemini (light green). The fraction of absolute problems improved is shown on top of each bar. The note at the bottom indicates that the results are shown for a training context size of 10 problems.
### Components/Axes
* **Title:** Percentage of problems where Meta-Tuning improves performance at each level: GPT-4 vs Gemini
* **X-axis:** Problem Level (categorical, levels 1 to 5)
* **Y-axis:** Improvement Percentage (%) (numerical, scale from 0 to 25)
* **Legend:** Located at the top-right of the chart.
* GPT-4 (sky blue)
* Gemini (light green)
* **Note:** Located at the bottom of the chart. "Note: Results shown for training context size of 10 problems. The fraction of the absolute problems improved is shown on top of each bar."
### Detailed Analysis
Here's a breakdown of the data for each problem level:
* **Problem Level 1:**
* GPT-4 (sky blue): Approximately 9% improvement (1/11)
* Gemini (light green): Approximately 27% improvement (3/11)
* **Problem Level 2:**
* GPT-4 (sky blue): Approximately 4.5% improvement (1/22)
* Gemini (light green): Approximately 9% improvement (2/22)
* **Problem Level 3:**
* GPT-4 (sky blue): Approximately 26% improvement (4/15)
* Gemini (light green): Approximately 7% improvement (1/15)
* **Problem Level 4:**
* GPT-4 (sky blue): Approximately 14.5% improvement (3/21)
* Gemini (light green): Approximately 5% improvement (1/21)
* **Problem Level 5:**
* GPT-4 (sky blue): Approximately 23.5% improvement (5/21)
* Gemini (light green): Approximately 14.5% improvement (3/21)
### Key Observations
* Gemini shows a significantly higher improvement percentage than GPT-4 at Problem Level 1.
* GPT-4 shows a higher improvement percentage than Gemini at Problem Levels 3, 4, and 5.
* Both models show relatively low improvement percentages at Problem Level 2.
### Interpretation
The chart compares the performance of Meta-Tuning on GPT-4 and Gemini across different problem levels. The data suggests that the effectiveness of Meta-Tuning varies significantly between the two models and across different problem levels. Gemini initially performs better at the lowest problem level, but GPT-4 surpasses Gemini's performance at higher problem levels. The fractions above each bar indicate the proportion of problems improved by Meta-Tuning for each model at each level, providing additional context to the percentage improvements. The note indicates that the results are based on a training context size of 10 problems, which is important to consider when interpreting the results.