\n
## Bar Chart: Meta-Tuning Performance Improvement - GPT-4 vs Gemini
### Overview
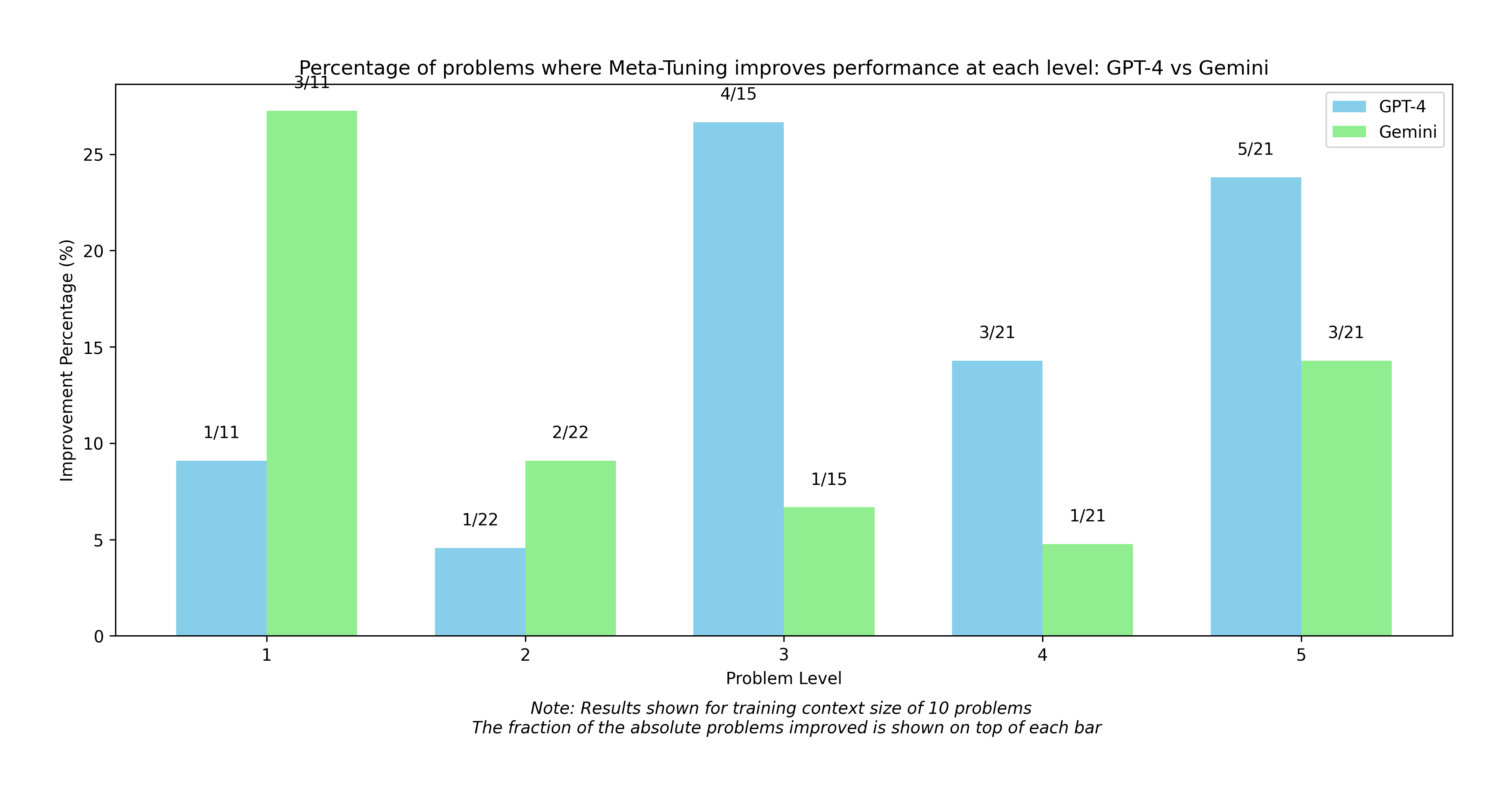
This bar chart compares the percentage of problems where meta-tuning improves performance for GPT-4 and Gemini across five problem levels. The chart displays improvement percentages on the y-axis and problem levels on the x-axis, using paired bars for each model at each level. Fractional values representing the number of improved problems out of the total are displayed above each bar.
### Components/Axes
* **Title:** "Percentage of problems where Meta-Tuning improves performance at each level: GPT-4 vs Gemini" (Top-center)
* **X-axis Label:** "Problem Level" (Bottom-center)
* **X-axis Markers:** 1, 2, 3, 4, 5 (Equally spaced along the x-axis)
* **Y-axis Label:** "Improvement Percentage (%)" (Left-center)
* **Y-axis Scale:** 0 to 30, with increments of 5.
* **Legend:** Located in the top-right corner.
* **GPT-4:** Represented by a light green color.
* **Gemini:** Represented by a light blue color.
* **Data Labels:** Fractions displayed above each bar (e.g., "3/11", "4/15").
* **Note:** "Note: Results shown for training context size of 10 problems. The fraction of the absolute problems improved is shown on top of each bar" (Bottom-center)
### Detailed Analysis
The chart presents paired bars for GPT-4 (green) and Gemini (blue) at each of the five problem levels.
* **Problem Level 1:** GPT-4 shows a significantly higher improvement percentage (approximately 27%) compared to Gemini (approximately 8%). The data label shows 3/11 for GPT-4 and 1/11 for Gemini.
* **Problem Level 2:** Gemini shows a slightly higher improvement percentage (approximately 9%) compared to GPT-4 (approximately 4%). The data label shows 1/22 for GPT-4 and 2/22 for Gemini.
* **Problem Level 3:** Gemini shows a higher improvement percentage (approximately 27%) compared to GPT-4 (approximately 7%). The data label shows 1/15 for GPT-4 and 4/15 for Gemini.
* **Problem Level 4:** Gemini shows a higher improvement percentage (approximately 14%) compared to GPT-4 (approximately 5%). The data label shows 1/21 for GPT-4 and 3/21 for Gemini.
* **Problem Level 5:** Gemini shows a higher improvement percentage (approximately 26%) compared to GPT-4 (approximately 16%). The data label shows 5/21 for Gemini and 3/21 for GPT-4.
### Key Observations
* GPT-4 consistently outperforms Gemini at Problem Level 1.
* Gemini consistently outperforms GPT-4 at Problem Levels 2, 3, 4, and 5.
* The improvement percentages vary significantly across problem levels for both models.
* The fractional data labels indicate the number of problems improved out of a total of 10-22 problems, depending on the level.
### Interpretation
The data suggests that meta-tuning is more effective for Gemini on more complex problems (levels 2-5), while GPT-4 shows a stronger initial improvement on simpler problems (level 1). The note indicates that these results are based on a training context size of 10 problems. The fractional data labels provide a more granular view of the improvement, showing the actual number of problems where performance was enhanced. The difference in performance between the two models across different problem levels could be due to variations in their underlying architectures and training data. The relatively small sample sizes (denominators of 11, 15, 21, and 22) suggest that these results should be interpreted with caution, and further investigation with larger datasets may be necessary to confirm these trends. The chart highlights the importance of considering problem complexity when evaluating the effectiveness of meta-tuning for different language models.