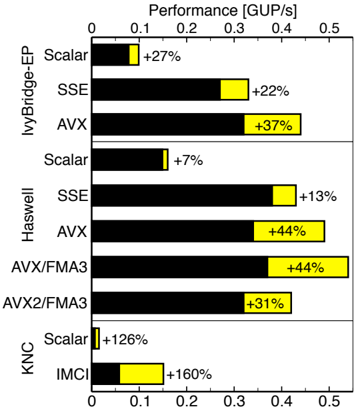
## Bar Chart: Performance Improvements in GUP/s Across Architectures and Methods
### Overview
The chart compares performance improvements (in Giga Operations per Second, GUP/s) for three processor architectures (IvyBridge-EP, Haswell, KNC) using different computational methods (Scalar, SSE, AVX, AVX/FMA3, IMCI). Each bar represents a method's performance relative to a baseline (Scalar), with percentage increases highlighted in yellow.
### Components/Axes
- **X-axis**: Performance [GUP/s], scaled from 0 to 0.5 in increments of 0.1.
- **Y-axis**: System-Method combinations, grouped by architecture:
- **IvyBridge-EP**: Scalar, SSE, AVX
- **Haswell**: Scalar, SSE, AVX, AVX/FMA3, AVX2/FMA3
- **KNC**: Scalar, IMCI
- **Legend**:
- **Black**: Baseline performance (Scalar).
- **Yellow**: Percentage improvement over Scalar.
### Detailed Analysis
1. **IvyBridge-EP**:
- **Scalar**: ~0.05 GUP/s (baseline).
- **SSE**: ~0.3 GUP/s (+22%).
- **AVX**: ~0.4 GUP/s (+37%).
2. **Haswell**:
- **Scalar**: ~0.15 GUP/s (+7%).
- **SSE**: ~0.4 GUP/s (+13%).
- **AVX**: ~0.45 GUP/s (+44%).
- **AVX/FMA3**: ~0.45 GUP/s (+44%).
- **AVX2/FMA3**: ~0.4 GUP/s (+31%).
3. **KNC**:
- **Scalar**: ~0.01 GUP/s (+126%).
- **IMCI**: ~0.15 GUP/s (+160%).
### Key Observations
- **Highest Performance**: KNC's IMCI achieves the highest absolute performance (~0.15 GUP/s) with a 160% improvement over its Scalar baseline.
- **Consistent Gains**: AVX/FMA3 and AVX methods show similar performance improvements (~44%) in Haswell, suggesting FMA3 optimizations are impactful.
- **Outliers**: KNC's Scalar baseline is anomalously low (~0.01 GUP/s) compared to other architectures, yet its IMCI method achieves a massive 160% gain.
- **Trends**: Performance increases with method complexity (e.g., Scalar < SSE < AVX < AVX/FMA3 in IvyBridge-EP and Haswell).
### Interpretation
The data highlights architectural and methodological advancements in computational efficiency:
- **KNC's IMCI** demonstrates the most significant leap, likely due to architectural innovations (e.g., specialized cores) or highly optimized algorithms.
- **AVX/FMA3** methods in Haswell and IvyBridge-EP show diminishing returns compared to KNC, indicating that newer architectures may better exploit advanced instruction sets.
- The **126% improvement** for KNC's Scalar suggests a redefinition of baseline performance, possibly due to architectural changes (e.g., clock speed, cache hierarchy).
- **SSE** and **AVX** methods show moderate gains, emphasizing the role of vectorization in performance scaling.
This chart underscores the interplay between hardware architecture and software optimization, with KNC's IMCI representing a paradigm shift in computational throughput.