TECHNICAL ASSET FINGERPRINT
4788fe5367175a1c955d5656
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
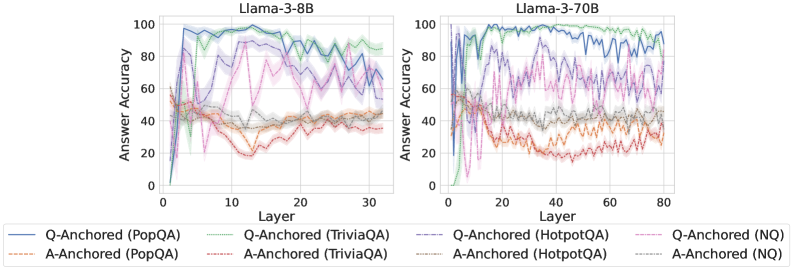
## Line Chart: Answer Accuracy vs. Layer for Llama Models
### Overview
This image presents two line charts comparing the answer accuracy of different question-answering (QA) datasets across layers of two Llama models: Llama-3-8B and Llama-3-70B. The x-axis represents the layer number, and the y-axis represents the answer accuracy, ranging from 0 to 100. Each line represents a specific QA dataset and anchoring method.
### Components/Axes
* **X-axis:** Layer (ranging from approximately 0 to 30 for Llama-3-8B and 0 to 80 for Llama-3-70B).
* **Y-axis:** Answer Accuracy (ranging from 0 to 100).
* **Left Chart Title:** Llama-3-8B
* **Right Chart Title:** Llama-3-70B
* **Legend:** Located at the bottom of the image, containing the following labels and corresponding line colors:
* Q-Anchored (PopQA) - Blue
* A-Anchored (PopQA) - Orange
* Q-Anchored (TriviaQA) - Green
* A-Anchored (TriviaQA) - Purple
* Q-Anchored (HotpotQA) - Dashed Red
* A-Anchored (HotpotQA) - Dashed Brown
* Q-Anchored (NQ) - Gray
* A-Anchored (NQ) - Light Orange
### Detailed Analysis or Content Details
**Llama-3-8B Chart (Left):**
* **Q-Anchored (PopQA) - Blue:** Starts at approximately 0 accuracy at layer 0, rapidly increases to around 95-100 accuracy by layer 5, and then fluctuates between approximately 70-100 accuracy for the remaining layers.
* **A-Anchored (PopQA) - Orange:** Starts at approximately 0 accuracy at layer 0, gradually increases to around 40 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers.
* **Q-Anchored (TriviaQA) - Green:** Starts at approximately 0 accuracy at layer 0, increases to around 90-100 accuracy by layer 5, and then fluctuates between approximately 60-100 accuracy for the remaining layers.
* **A-Anchored (TriviaQA) - Purple:** Starts at approximately 0 accuracy at layer 0, increases to around 60 accuracy by layer 5, and then fluctuates between approximately 40-70 accuracy for the remaining layers.
* **Q-Anchored (HotpotQA) - Dashed Red:** Starts at approximately 0 accuracy at layer 0, increases to around 80-90 accuracy by layer 5, and then fluctuates between approximately 50-90 accuracy for the remaining layers.
* **A-Anchored (HotpotQA) - Dashed Brown:** Starts at approximately 0 accuracy at layer 0, increases to around 30 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers.
* **Q-Anchored (NQ) - Gray:** Starts at approximately 0 accuracy at layer 0, increases to around 80-90 accuracy by layer 5, and then fluctuates between approximately 50-90 accuracy for the remaining layers.
* **A-Anchored (NQ) - Light Orange:** Starts at approximately 0 accuracy at layer 0, gradually increases to around 40 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers.
**Llama-3-70B Chart (Right):**
* **Q-Anchored (PopQA) - Blue:** Starts at approximately 0 accuracy at layer 0, rapidly increases to around 95-100 accuracy by layer 5, and then fluctuates between approximately 70-100 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **A-Anchored (PopQA) - Orange:** Starts at approximately 0 accuracy at layer 0, gradually increases to around 40 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **Q-Anchored (TriviaQA) - Green:** Starts at approximately 0 accuracy at layer 0, increases to around 90-100 accuracy by layer 5, and then fluctuates between approximately 60-100 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **A-Anchored (TriviaQA) - Purple:** Starts at approximately 0 accuracy at layer 0, increases to around 60 accuracy by layer 5, and then fluctuates between approximately 40-70 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **Q-Anchored (HotpotQA) - Dashed Red:** Starts at approximately 0 accuracy at layer 0, increases to around 80-90 accuracy by layer 5, and then fluctuates between approximately 50-90 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **A-Anchored (HotpotQA) - Dashed Brown:** Starts at approximately 0 accuracy at layer 0, increases to around 30 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **Q-Anchored (NQ) - Gray:** Starts at approximately 0 accuracy at layer 0, increases to around 80-90 accuracy by layer 5, and then fluctuates between approximately 50-90 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
* **A-Anchored (NQ) - Light Orange:** Starts at approximately 0 accuracy at layer 0, gradually increases to around 40 accuracy by layer 5, and then remains relatively stable between approximately 20-40 accuracy for the remaining layers. The pattern is similar to the 8B model, but extends to layer 80.
### Key Observations
* **Q-Anchored consistently outperforms A-Anchored** across all datasets and models.
* **PopQA, TriviaQA, HotpotQA, and NQ all show a similar initial rapid increase in accuracy** up to layer 5.
* **After layer 5, the accuracy fluctuates**, suggesting that adding more layers beyond a certain point does not necessarily improve performance and may even introduce instability.
* **The 70B model exhibits similar trends to the 8B model**, but extends to a higher layer count (80).
* **A-Anchored accuracy remains relatively low** compared to Q-Anchored, consistently below 40.
### Interpretation
The data suggests that question anchoring (Q-Anchored) is a more effective strategy for improving answer accuracy in Llama models compared to answer anchoring (A-Anchored). The initial rapid increase in accuracy across all datasets indicates that the early layers of the models are crucial for learning basic question-answering capabilities. The subsequent fluctuations in accuracy suggest that deeper layers may be more sensitive to the specific dataset and require careful tuning. The similarity in trends between the 8B and 70B models indicates that the underlying learning dynamics are consistent across different model sizes, although the 70B model can be trained for more layers. The consistently low accuracy of A-Anchored suggests that this approach may not be as effective for capturing the nuances of question-answering tasks. The data highlights the importance of layer selection and anchoring strategies in optimizing the performance of Llama models for question-answering applications.
DECODING INTELLIGENCE...