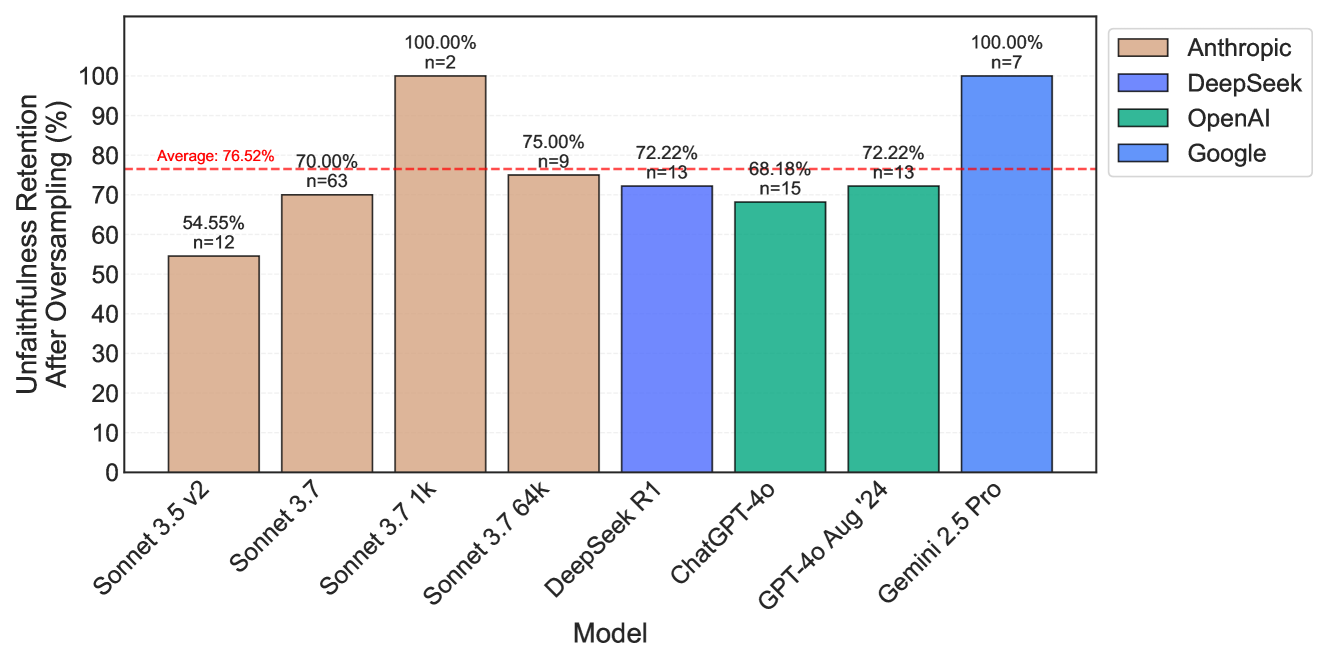
## Bar Chart: Unfaithfulness Retention After Oversampling
### Overview
This bar chart compares the "Unfaithfulness Retention After Oversampling (%)" across several language models: Sonnet 3.5 v2, Sonnet 3.7, Sonnet 3.7 1k, DeepSeek R1, ChatGPT-4o, GPT-4o Aug '24, and Gemini 2.5 Pro. Each bar represents the percentage retention, with the number of samples (n) indicated above each bar. A horizontal red dashed line indicates a 70% threshold. The chart is divided into four model providers: Anthropic (Sonnet models), DeepSeek, OpenAI (ChatGPT models), and Google (Gemini models).
### Components/Axes
* **X-axis:** Model (Sonnet 3.5 v2, Sonnet 3.7, Sonnet 3.7 1k, DeepSeek R1, ChatGPT-4o, GPT-4o Aug '24, Gemini 2.5 Pro)
* **Y-axis:** Unfaithfulness Retention After Oversampling (%) - Scale ranges from 0 to 100.
* **Legend:** Located in the top-right corner, identifying the color-coding for each model provider:
* Anthropic (Brown)
* DeepSeek (Orange)
* OpenAI (Green)
* Google (Blue)
* **Data Labels:** Percentage values are displayed on top of each bar, along with the sample size (n).
* **Threshold Line:** A horizontal red dashed line at 70%.
### Detailed Analysis
Here's a breakdown of the data for each model, verifying color consistency with the legend:
* **Sonnet 3.5 v2 (Anthropic - Brown):** 54.55%, n=12.
* **Sonnet 3.7 (Anthropic - Brown):** 76.52%, n=63.
* **Sonnet 3.7 1k (Anthropic - Brown):** 70.00%, n=2.
* **DeepSeek R1 (DeepSeek - Orange):** 75.00%, n=9.
* **ChatGPT-4o (OpenAI - Green):** 72.22%, n=13.
* **GPT-4o Aug '24 (OpenAI - Green):** 68.48%, n=15.
* **Gemini 2.5 Pro (Google - Blue):** 72.22%, n=13.
**Trends:**
* Anthropic's Sonnet 3.5 v2 shows the lowest retention rate.
* Sonnet 3.7 has a significantly higher retention rate than Sonnet 3.5 v2.
* Sonnet 3.7 1k has a retention rate of exactly 70%.
* DeepSeek R1, ChatGPT-4o, and Gemini 2.5 Pro all have retention rates around 72-75%.
* GPT-4o Aug '24 has the lowest retention rate among the OpenAI models.
### Key Observations
* The sample sizes (n) vary considerably between models, potentially impacting the reliability of the results. Sonnet 3.7 1k has a very small sample size (n=2).
* Anthropic's Sonnet models show a wide range of retention rates, with a large jump between 3.5 v2 and 3.7.
* The majority of models achieve retention rates above the 70% threshold.
* The OpenAI models show some variation, with GPT-4o Aug '24 performing slightly worse than ChatGPT-4o.
### Interpretation
The chart demonstrates the "Unfaithfulness Retention After Oversampling" performance of different language models. "Unfaithfulness Retention" likely refers to the model's ability to maintain the original intent or meaning of a prompt after a process called "oversampling" is applied. Oversampling is a technique used to balance datasets, potentially impacting the model's behavior.
The data suggests that some models are more robust to the effects of oversampling than others. Anthropic's Sonnet 3.5 v2 appears to be particularly sensitive, while Sonnet 3.7 shows significant improvement. The DeepSeek, OpenAI, and Google models generally perform well, with retention rates clustered around 70-75%.
The varying sample sizes are a critical consideration. The low 'n' value for Sonnet 3.7 1k makes its 70% retention rate less statistically significant. The large 'n' value for Sonnet 3.7 (n=63) lends more confidence to its 76.52% retention rate.
The 70% threshold line is likely a benchmark or target value for acceptable performance. The fact that most models exceed this threshold suggests that oversampling, in this context, doesn't drastically degrade performance for these models. However, the differences between models indicate that some are better equipped to handle this process than others. Further investigation would be needed to understand *why* these differences exist and what specific aspects of the models contribute to their retention rates.