## Bar Chart: Unfaithfulness Retention After Oversampling (%)
### Overview
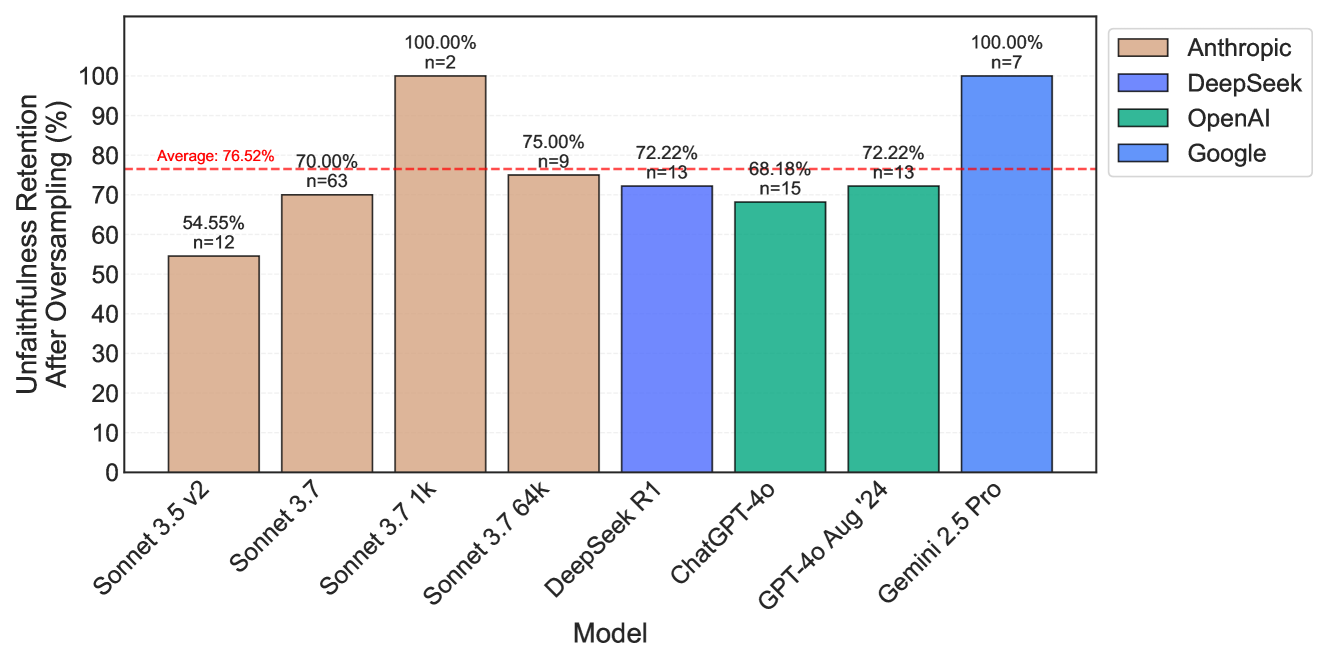
The chart compares unfaithfulness retention percentages across eight AI models from four companies (Anthropic, DeepSeek, OpenAI, Google) after oversampling. Retention is measured as a percentage, with a red dashed line indicating the average retention rate of 76.52%. Sample sizes (n) vary significantly across models.
### Components/Axes
- **X-axis**: Model names (e.g., "Sonnet 3.5 v2", "Sonnet 3.7 1k", "Gemini 2.5 Pro").
- **Y-axis**: Unfaithfulness retention percentage (0–100%).
- **Legend**:
- Anthropic (brown)
- DeepSeek (blue)
- OpenAI (green)
- Google (light blue)
- **Key Elements**:
- Red dashed line at 76.52% (average retention).
- Bar heights represent retention percentages.
- Sample sizes (n) listed above each bar.
### Detailed Analysis
1. **Anthropic Models**:
- **Sonnet 3.5 v2**: 54.55% (n=12).
- **Sonnet 3.7**: 70.00% (n=63).
- **Sonnet 3.7 1k**: 100.00% (n=2).
- **Sonnet 3.7 64k**: 75.00% (n=9).
- *Trend*: Mixed performance, with the smallest sample size (n=2) achieving perfect retention.
2. **DeepSeek**:
- **DeepSeek R1**: 72.22% (n=13).
- *Trend*: Mid-range retention with moderate sample size.
3. **OpenAI**:
- **ChatGPT-4o**: 68.18% (n=15).
- **GPT-4o Aug '24**: 72.22% (n=13).
- *Trend*: Lower retention compared to Anthropic and Google, with consistent sample sizes (n=13–15).
4. **Google**:
- **Gemini 2.5 Pro**: 100.00% (n=7).
- *Trend*: Perfect retention but with a small sample size (n=7).
### Key Observations
- **High Performers**:
- Anthropic's "Sonnet 3.7 1k" and Google's "Gemini 2.5 Pro" achieve 100% retention, but both have small sample sizes (n=2 and n=7, respectively).
- **Low Performers**:
- Anthropic's "Sonnet 3.5 v2" (54.55%) and OpenAI's "ChatGPT-4o" (68.18%) fall below the average.
- **Average Retention**: The red dashed line at 76.52% suggests most models cluster around this value, except for outliers like the 100% performers.
- **Sample Size Variability**: Larger samples (e.g., n=63 for Sonnet 3.7) may indicate more reliable data, while smaller samples (n=2–7) raise questions about statistical significance.
### Interpretation
The data highlights trade-offs between model performance and sample size reliability. While Anthropic and Google models show higher retention rates, their small sample sizes (especially for 100% results) limit confidence in these findings. OpenAI models consistently underperform relative to the average, suggesting potential weaknesses in their oversampling strategies. The average line (76.52%) serves as a benchmark, but the lack of error bars or confidence intervals makes it difficult to assess the precision of these estimates. Further analysis with larger datasets or statistical validation would strengthen these conclusions.