TECHNICAL ASSET FINGERPRINT
4840bb274928c4fb17aafe4e
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
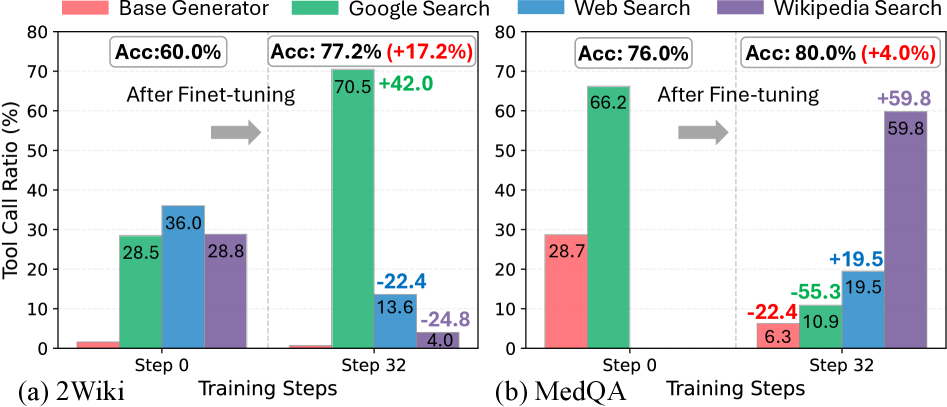
## Grouped Bar Chart: Tool Call Ratio Comparison Across Training Steps
### Overview
The image displays two side-by-side grouped bar charts comparing the "Tool Call Ratio (%)" for four different tools across two training steps (Step 0 and Step 32) for two distinct datasets: (a) 2Wiki and (b) MedQA. The charts illustrate the change in tool usage frequency after a fine-tuning process, with overall accuracy improvements noted for each dataset.
### Components/Axes
* **Chart Type:** Grouped Bar Chart (two panels).
* **Y-Axis:** Labeled "Tool Call Ratio (%)". Scale ranges from 0 to 80, with major tick marks every 10 units.
* **X-Axis:** Labeled "Training Steps". Each panel shows two discrete points: "Step 0" and "Step 32".
* **Legend:** Positioned at the top center of the entire figure, spanning both panels. It defines four tool categories by color:
* **Base Generator:** Red/Salmon
* **Google Search:** Green
* **Web Search:** Blue
* **Wikipedia Search:** Purple
* **Panel Labels:**
* Left panel is labeled "(a) 2Wiki" at the bottom left.
* Right panel is labeled "(b) MedQA" at the bottom left.
* **Accuracy Annotations:** Above each set of bars for Step 0 and Step 32, text boxes display the overall accuracy ("Acc:") and the change in accuracy after fine-tuning (in parentheses with a +/- sign).
### Detailed Analysis
#### Panel (a): 2Wiki Dataset
* **Step 0:**
* **Base Generator (Red):** Very low ratio, approximately 1-2%.
* **Google Search (Green):** 28.5%
* **Web Search (Blue):** 36.0%
* **Wikipedia Search (Purple):** 28.8%
* **Overall Accuracy:** 60.0%
* **Step 32 (After Fine-tuning):**
* **Base Generator (Red):** Remains very low, near 0%.
* **Google Search (Green):** 70.5% (Annotated change: **+42.0**)
* **Web Search (Blue):** 13.6% (Annotated change: **-22.4**)
* **Wikipedia Search (Purple):** 4.0% (Annotated change: **-24.8**)
* **Overall Accuracy:** 77.2% (Annotated improvement: **+17.2%**)
* **Trend Verification:** The green bar (Google Search) shows a dramatic upward slope from Step 0 to Step 32. The blue (Web Search) and purple (Wikipedia Search) bars show significant downward slopes. The red bar (Base Generator) remains consistently negligible.
#### Panel (b): MedQA Dataset
* **Step 0:**
* **Base Generator (Red):** 28.7%
* **Google Search (Green):** 66.2%
* **Web Search (Blue):** Not visibly present (ratio ~0%).
* **Wikipedia Search (Purple):** Not visibly present (ratio ~0%).
* **Overall Accuracy:** 76.0%
* **Step 32 (After Fine-tuning):**
* **Base Generator (Red):** 6.3% (Annotated change: **-22.4**)
* **Google Search (Green):** 10.9% (Annotated change: **-55.3**)
* **Web Search (Blue):** 19.5% (Annotated change: **+19.5**)
* **Wikipedia Search (Purple):** 59.8% (Annotated change: **+59.8**)
* **Overall Accuracy:** 80.0% (Annotated improvement: **+4.0%**)
* **Trend Verification:** The green bar (Google Search) shows a steep downward slope. The red bar (Base Generator) also slopes downward. The blue (Web Search) and purple (Wikipedia Search) bars show very strong upward slopes from near-zero to significant values.
### Key Observations
1. **Divergent Tool Reliance Post-Fine-Tuning:** The fine-tuning process causes a dramatic shift in which tool is predominantly called, and this shift is dataset-dependent.
* For **2Wiki**, reliance shifts overwhelmingly to **Google Search** (from 28.5% to 70.5%), while Web and Wikipedia Search usage collapses.
* For **MedQA**, reliance shifts overwhelmingly to **Wikipedia Search** (from ~0% to 59.8%), while Google Search and Base Generator usage plummet.
2. **Accuracy Improvements:** Both datasets show improved accuracy after fine-tuning, but the magnitude differs. 2Wiki sees a large +17.2% gain, while MedQA sees a more modest +4.0% gain.
3. **Base Generator Role:** The Base Generator's tool call ratio is minimal for 2Wiki at both steps. For MedQA, it starts as a significant contributor (28.7%) but is largely replaced by specialized search tools after fine-tuning.
4. **Complementary Tool Pairs:** In the final state (Step 32), each dataset shows one dominant tool (Google for 2Wiki, Wikipedia for MedQA) and one secondary tool (Web Search for MedQA at 19.5%), with the others minimized.
### Interpretation
This data suggests that fine-tuning a model to use tools effectively involves not just improving overall accuracy, but also learning to **specialize its tool-calling strategy based on the domain of the task**.
* **Domain-Specific Tool Efficacy:** The 2Wiki dataset (likely involving multi-hop factual questions across wikis) benefits most from broad web search via Google. In contrast, the MedQA dataset (medical question answering) benefits most from the curated, authoritative knowledge found in Wikipedia, suggesting that for specialized domains, targeted knowledge sources are more valuable than general web search.
* **Efficiency and Precision:** The fine-tuning process appears to make the model more efficient and precise in its tool selection. It moves from a more diffuse or default strategy (using Base Generator or a single search tool heavily) to a strategy that heavily favors the tool most predictive of success for that specific domain. The reduction in calls to less effective tools (e.g., Web Search for 2Wiki) indicates the model is learning to avoid noisy or unhelpful retrieval paths.
* **Trade-off Between Generality and Specialization:** The Base Generator, which likely represents the model's internal parametric knowledge, is deprioritized in favor of external retrieval after fine-tuning. This is especially stark in MedQA, where the model almost completely abandons its internal generator for Wikipedia. This implies that for factual, knowledge-intensive tasks, fine-tuning teaches the model to rely more on verified external sources than its own potentially outdated or incomplete parameters.
* **Performance Ceiling:** The smaller accuracy gain for MedQA (+4.0%) despite a massive change in tool strategy could indicate that the task is inherently harder, or that the initial tool strategy (heavy Google Search) was already reasonably effective, leaving less room for improvement. The large gain for 2Wiki suggests its initial strategy was suboptimal.
In summary, the charts demonstrate that effective tool-use fine-tuning is a process of **domain-aware specialization**, where the model learns to dynamically reconfigure its retrieval strategy to align with the knowledge sources most relevant to the task at hand, leading to measurable performance gains.
DECODING INTELLIGENCE...