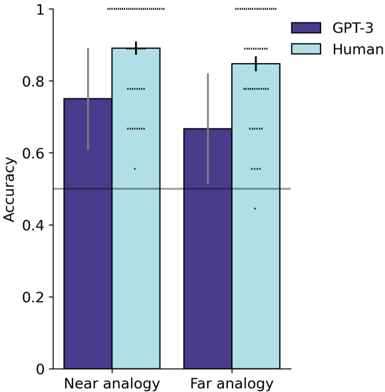
## Bar Chart: GPT-3 vs. Human Accuracy on Analogy Tasks
### Overview
The image is a bar chart comparing the accuracy of GPT-3 and humans on near and far analogy tasks. The chart displays accuracy scores on the y-axis, ranging from 0 to 1, and the type of analogy (near vs. far) on the x-axis. Error bars are included to indicate variability.
### Components/Axes
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2. A horizontal line is present at the 0.5 accuracy level.
* **X-axis:** Categorical, with two categories: "Near analogy" and "Far analogy".
* **Legend:** Located in the top-right corner, indicating:
* Dark Blue: "GPT-3"
* Light Blue: "Human"
* **Error Bars:** Vertical lines extending above and below the tops of the bars, indicating the standard deviation or confidence interval.
### Detailed Analysis
* **Near Analogy:**
* GPT-3 (Dark Blue): Accuracy is approximately 0.75, with an error bar extending from roughly 0.6 to 0.9.
* Human (Light Blue): Accuracy is approximately 0.89, with a smaller error bar extending from roughly 0.85 to 0.93.
* **Far Analogy:**
* GPT-3 (Dark Blue): Accuracy is approximately 0.67, with an error bar extending from roughly 0.5 to 0.82.
* Human (Light Blue): Accuracy is approximately 0.85, with a smaller error bar extending from roughly 0.8 to 0.9.
### Key Observations
* Humans consistently outperform GPT-3 in both near and far analogy tasks.
* The difference in accuracy between humans and GPT-3 is more pronounced in far analogy tasks.
* The error bars for GPT-3 are larger than those for humans, suggesting greater variability in GPT-3's performance.
### Interpretation
The data suggests that while GPT-3 can perform analogy tasks, it is not as accurate or consistent as humans, especially when dealing with more distant or abstract analogies. The higher accuracy of humans indicates a superior ability to understand and apply relational reasoning in these contexts. The error bars suggest that GPT-3's performance is more variable, possibly indicating a sensitivity to specific task formulations or a lack of robustness in its reasoning process. The horizontal line at 0.5 accuracy could represent a baseline or chance level, highlighting that both GPT-3 and humans perform well above chance.