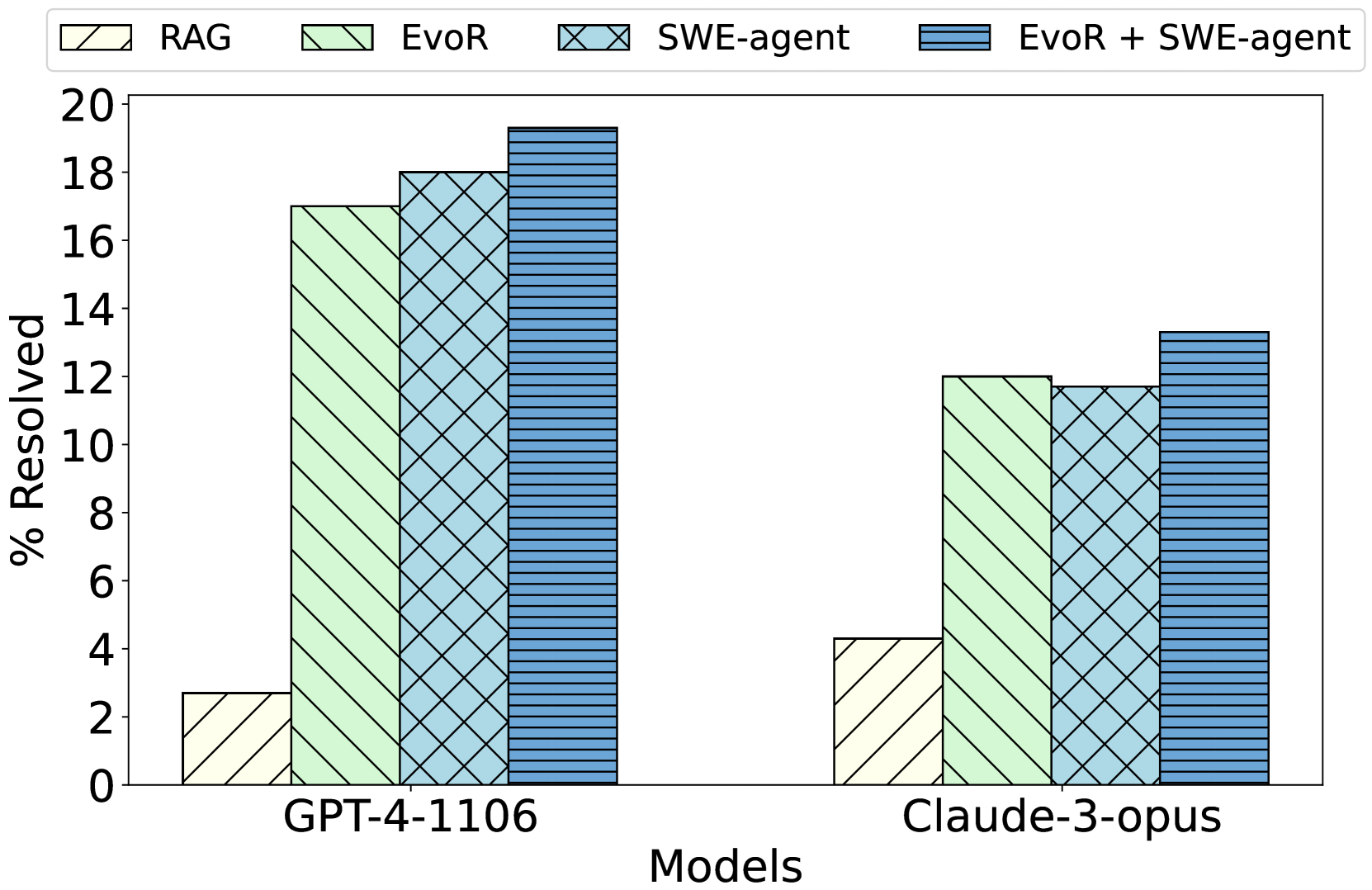
## Bar Chart: Model Performance Comparison
### Overview
The chart compares the performance of two AI models (GPT-4-1106 and Claude-3-opus) across four resolution strategies: RAG, EvoR, SWE-agent, and EvoR + SWE-agent. Performance is measured as "% Resolved" on a 0-20 scale.
### Components/Axes
- **X-axis**: Models (GPT-4-1106, Claude-3-opus)
- **Y-axis**: "% Resolved" (0-20 scale)
- **Legend**:
- RAG (light yellow, diagonal stripes)
- EvoR (light green, diagonal stripes)
- SWE-agent (light blue, crosshatch)
- EvoR + SWE-agent (dark blue, horizontal stripes)
- **Bar Groups**: Each model has four clustered bars representing the four strategies.
### Detailed Analysis
1. **GPT-4-1106**:
- RAG: ~2.5% (light yellow)
- EvoR: ~17% (light green)
- SWE-agent: ~18% (light blue)
- EvoR + SWE-agent: ~19.5% (dark blue)
2. **Claude-3-opus**:
- RAG: ~4% (light yellow)
- EvoR: ~12% (light green)
- SWE-agent: ~11.5% (light blue)
- EvoR + SWE-agent: ~13.5% (dark blue)
### Key Observations
- **EvoR + SWE-agent** consistently yields the highest "% Resolved" for both models.
- **RAG** performs worst across all models, with GPT-4-1106 showing the lowest value (~2.5%).
- GPT-4-1106 outperforms Claude-3-opus in all strategies except RAG, where Claude-3-opus has a slight edge (~4% vs. ~2.5%).
- The combination of EvoR and SWE-agent improves performance by ~2-3% over using either strategy alone.
### Interpretation
The data demonstrates that integrating EvoR with SWE-agent significantly enhances resolution rates, particularly for the GPT-4-1106 model. This suggests synergistic benefits between the two strategies. While Claude-3-opus shows lower overall performance, it follows the same trend, indicating the combination's effectiveness is model-agnostic. RAG's poor performance highlights its limitations compared to the other strategies. The results imply that hybrid approaches (EvoR + SWE-agent) should be prioritized for tasks requiring high resolution rates.