\n
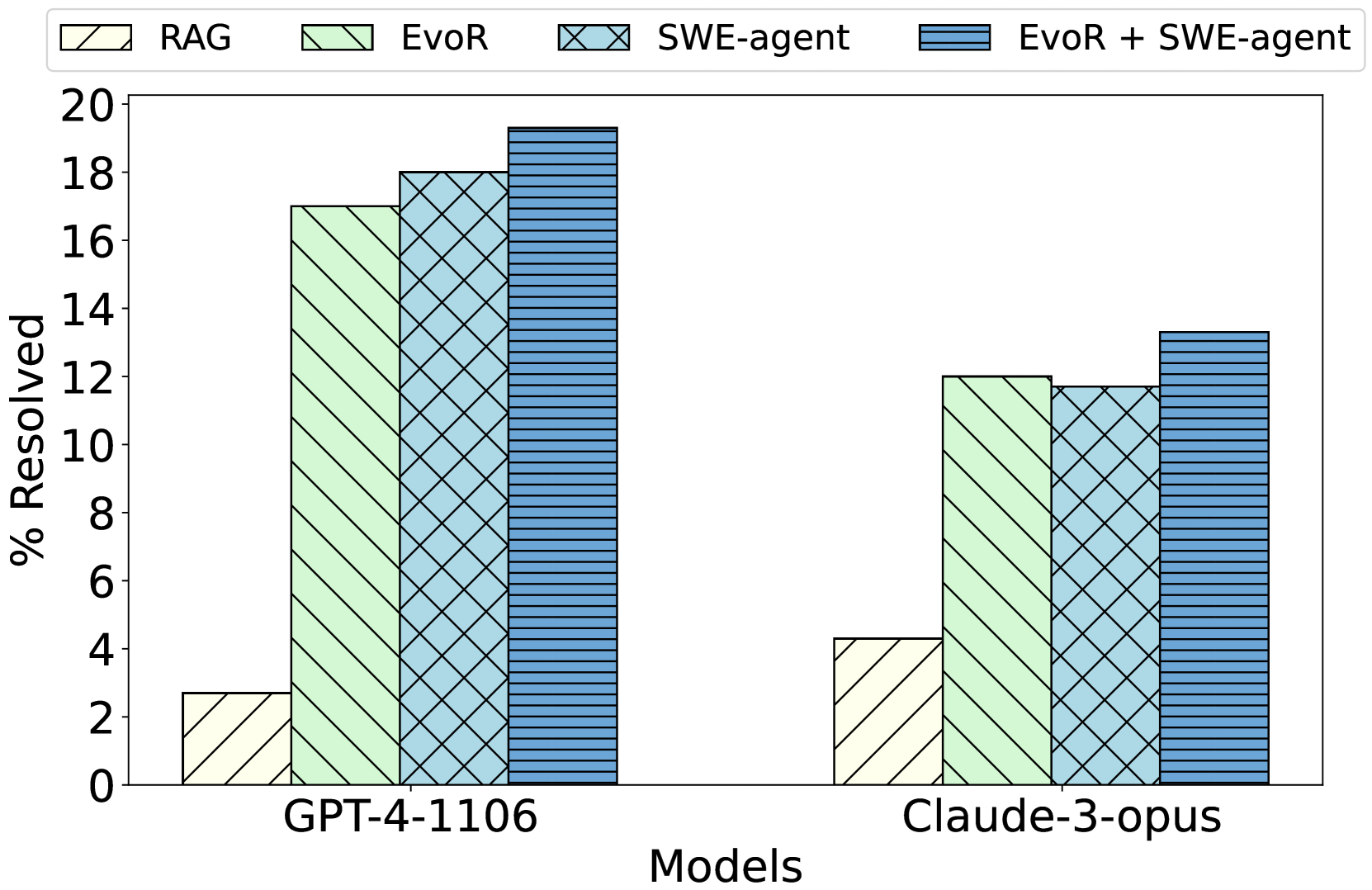
## Bar Chart: Resolution Performance of Language Models
### Overview
This bar chart compares the percentage of resolved issues for different language models (GPT-4-1106 and Claude-3-opus) using four different approaches: RAG, EvoR, SWE-agent, and EvoR + SWE-agent. The chart uses stacked bars to show the contribution of each approach to the overall resolution percentage.
### Components/Axes
* **X-axis:** Models - GPT-4-1106 and Claude-3-opus.
* **Y-axis:** % Resolved - ranging from 0 to 20.
* **Legend:** Located at the top of the chart, indicating the color-coding for each approach:
* RAG (White)
* EvoR (Light Green)
* SWE-agent (Light Blue with diagonal lines)
* EvoR + SWE-agent (Dark Blue)
### Detailed Analysis
The chart consists of two sets of stacked bars, one for each model.
**GPT-4-1106:**
* **RAG:** The RAG approach resolves approximately 2% of issues (white portion of the bar).
* **EvoR:** The EvoR approach resolves approximately 15% of issues (light green portion of the bar).
* **SWE-agent:** The SWE-agent approach resolves approximately 17% of issues (light blue with diagonal lines portion of the bar).
* **EvoR + SWE-agent:** The combined EvoR + SWE-agent approach resolves approximately 19% of issues (dark blue portion of the bar).
**Claude-3-opus:**
* **RAG:** The RAG approach resolves approximately 4% of issues (white portion of the bar).
* **EvoR:** The EvoR approach resolves approximately 8% of issues (light green portion of the bar).
* **SWE-agent:** The SWE-agent approach resolves approximately 12% of issues (light blue with diagonal lines portion of the bar).
* **EvoR + SWE-agent:** The combined EvoR + SWE-agent approach resolves approximately 13% of issues (dark blue portion of the bar).
### Key Observations
* The EvoR + SWE-agent approach consistently yields the highest resolution percentage for both models.
* GPT-4-1106 generally outperforms Claude-3-opus across all approaches.
* RAG consistently has the lowest resolution percentage for both models.
* The SWE-agent approach shows a significant improvement over EvoR alone for both models.
### Interpretation
The data suggests that combining EvoR and SWE-agent is the most effective strategy for resolving issues with these language models. GPT-4-1106 demonstrates superior performance compared to Claude-3-opus, regardless of the approach used. The relatively low performance of RAG indicates that it may not be the most suitable approach for this particular task. The consistent improvement observed when SWE-agent is added to EvoR suggests a synergistic effect between the two approaches. The differences in performance between the models could be attributed to variations in their underlying architectures, training data, or capabilities. The chart provides a clear comparison of the effectiveness of different approaches for issue resolution, allowing for informed decision-making regarding model selection and strategy implementation.