## Bar Chart: CoTs without a valid label on ProcessBench
### Overview
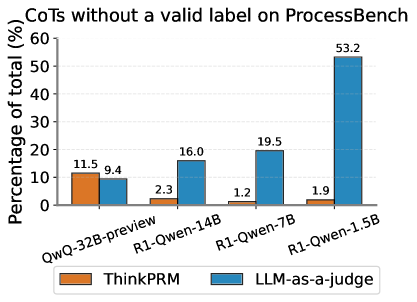
The image is a bar chart comparing the percentage of Chains of Thought (CoTs) without a valid label on ProcessBench for different language models, evaluated using two methods: ThinkPRM (orange bars) and LLM-as-a-judge (blue bars). The x-axis represents the language models, and the y-axis represents the percentage of total CoTs without a valid label.
### Components/Axes
* **Title:** CoTs without a valid label on ProcessBench
* **X-axis:** Language Models: QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, R1-Qwen-1.5B
* **Y-axis:** Percentage of total (%)
* Scale: 0% to 60%, with gridlines at intervals of 10%.
* **Legend:** Located at the bottom of the chart.
* Orange: ThinkPRM
* Blue: LLM-as-a-judge
### Detailed Analysis
Here's a breakdown of the data for each language model and evaluation method:
* **QwQ-32B-preview:**
* ThinkPRM (orange): 11.5%
* LLM-as-a-judge (blue): 9.4%
* **R1-Qwen-14B:**
* ThinkPRM (orange): 2.3%
* LLM-as-a-judge (blue): 16.0%
* **R1-Qwen-7B:**
* ThinkPRM (orange): 1.2%
* LLM-as-a-judge (blue): 19.5%
* **R1-Qwen-1.5B:**
* ThinkPRM (orange): 1.9%
* LLM-as-a-judge (blue): 53.2%
### Key Observations
* For QwQ-32B-preview, ThinkPRM reports a slightly higher percentage of invalid labels compared to LLM-as-a-judge.
* For R1-Qwen-14B, R1-Qwen-7B, and R1-Qwen-1.5B, LLM-as-a-judge reports a significantly higher percentage of invalid labels compared to ThinkPRM.
* The percentage of invalid labels reported by LLM-as-a-judge increases dramatically for R1-Qwen-1.5B.
### Interpretation
The chart suggests that the LLM-as-a-judge method is more sensitive to identifying invalid labels in CoTs, especially for larger models like R1-Qwen-1.5B. This could indicate that larger models generate more complex or nuanced CoTs that are more difficult for the ThinkPRM method to validate. The significant difference in invalid label percentages between the two methods highlights the importance of the evaluation method used when assessing the quality of CoTs generated by language models. The R1-Qwen-1.5B model shows a particularly high rate of invalid labels when evaluated by LLM-as-a-judge, suggesting potential issues with the quality or structure of its generated CoTs.