\n
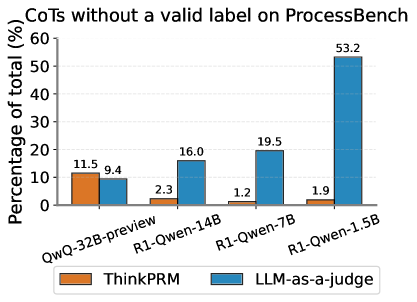
## Bar Chart: CoTs without a valid label on ProcessBench
### Overview
This bar chart visualizes the percentage of total CoTs (Chain of Thoughts) without a valid label on the ProcessBench dataset, for different model configurations. Two evaluation methods, "ThinkPRM" and "LLM-as-a-judge", are compared across four model versions: QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, and R1-Qwen-1.5B. The y-axis represents the percentage of total CoTs, ranging from 0% to 60%.
### Components/Axes
* **Title:** "CoTs without a valid label on ProcessBench" (Top-center)
* **X-axis Label:** Model Configurations (Bottom-center)
* Categories: QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, R1-Qwen-1.5B
* **Y-axis Label:** "Percentage of total (%)" (Left-center)
* Scale: 0%, 10%, 20%, 30%, 40%, 50%, 60%
* **Legend:** (Bottom-left)
* "ThinkPRM" - Orange
* "LLM-as-a-judge" - Blue
### Detailed Analysis
The chart consists of paired bars for each model configuration, representing the results from "ThinkPRM" and "LLM-as-a-judge".
* **QwQ-32B-preview:**
* ThinkPRM: Approximately 11.5% (Orange bar)
* LLM-as-a-judge: Approximately 9.4% (Blue bar)
* **R1-Qwen-14B:**
* ThinkPRM: Approximately 2.3% (Orange bar)
* LLM-as-a-judge: Approximately 16.0% (Blue bar)
* **R1-Qwen-7B:**
* ThinkPRM: Approximately 1.2% (Orange bar)
* LLM-as-a-judge: Approximately 19.5% (Blue bar)
* **R1-Qwen-1.5B:**
* ThinkPRM: Approximately 1.9% (Orange bar)
* LLM-as-a-judge: Approximately 53.2% (Blue bar)
The "LLM-as-a-judge" bars generally increase in height from left to right, with a particularly large jump for R1-Qwen-1.5B. The "ThinkPRM" bars remain relatively low and consistent across all model configurations.
### Key Observations
* The percentage of CoTs without a valid label is significantly higher when evaluated using "LLM-as-a-judge", especially for the R1-Qwen-1.5B model.
* "ThinkPRM" consistently reports a low percentage of invalid labels across all models.
* There is a clear trend of increasing invalid labels with "LLM-as-a-judge" as the model size decreases (from QwQ-32B-preview to R1-Qwen-1.5B).
### Interpretation
The data suggests a discrepancy in how "ThinkPRM" and "LLM-as-a-judge" evaluate the validity of labels in CoTs on the ProcessBench dataset. "LLM-as-a-judge" appears to be more sensitive to label issues, or perhaps more critical in its assessment, leading to a higher percentage of flagged invalid labels. The increasing trend of invalid labels for "LLM-as-a-judge" with smaller models could indicate that smaller models generate CoTs with less consistent or accurate labeling, which are then more readily identified as invalid by the LLM judge. Alternatively, it could be that the LLM judge is more prone to false positives when evaluating the output of smaller models. The consistently low invalid label rate reported by "ThinkPRM" suggests it may be less effective at detecting these issues, or that it uses a different criteria for label validity. This difference in evaluation methods highlights the importance of considering the evaluation metric when assessing the performance of CoT generation models.