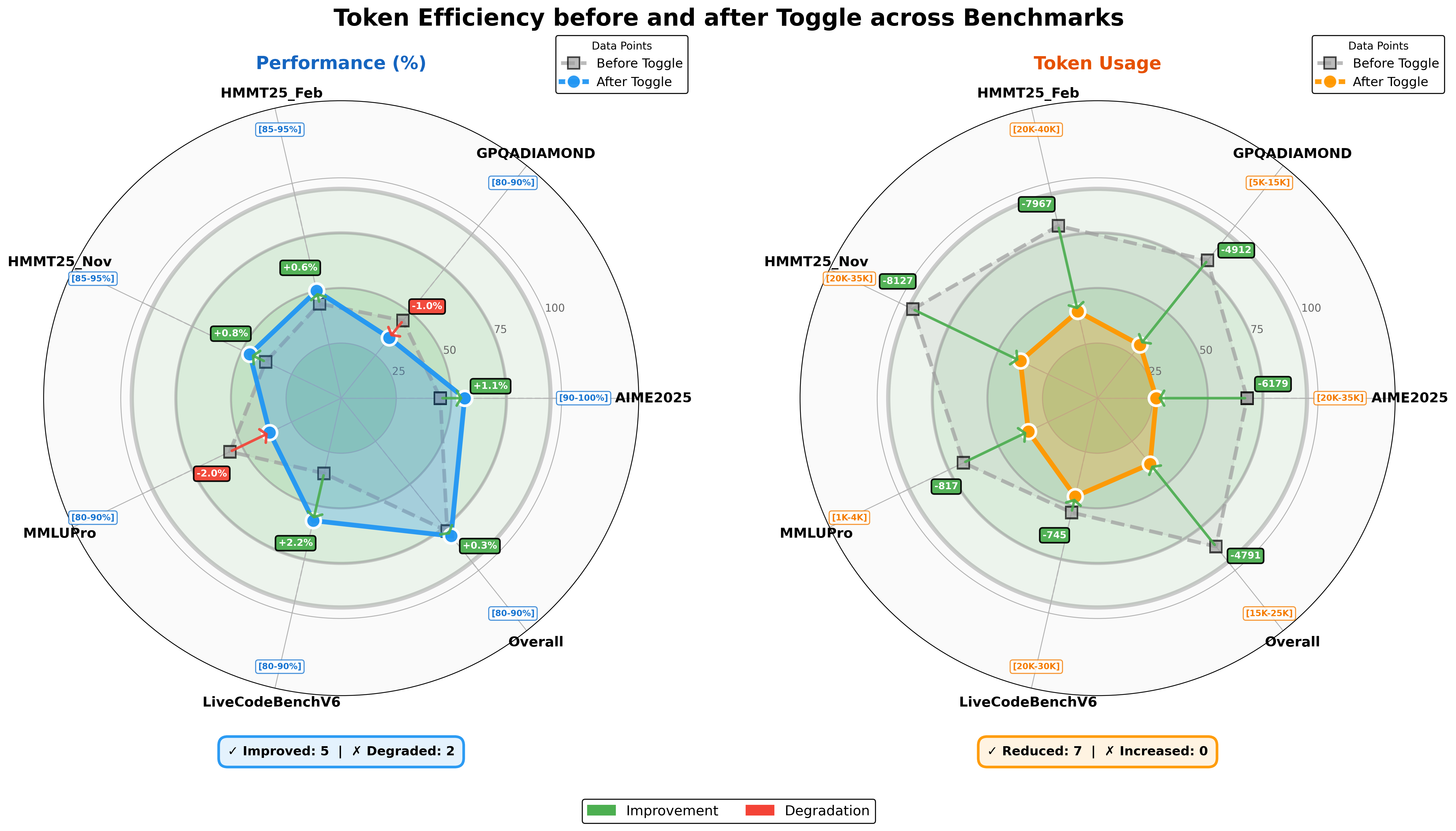
## [Dual Radar Chart]: Token Efficiency before and after Toggle across Benchmarks
### Overview
The image contains two side-by-side radar (spider) charts comparing system performance (left, in %) and token usage (right, in numerical values) **before** (gray squares) and **after** (blue/orange circles) a “Toggle” (configuration/model change) across seven benchmarks: *HMMT25_Feb, GPQADIAMOND, AIME2025, Overall, LiveCodeBenchV6, MMLUPro, HMMT25_Nov*.
### Components/Axes
#### Left Chart: Performance (%)
- **Axes**: Radial axes with benchmarks (HMMT25_Feb, GPQADIAMOND, AIME2025, Overall, LiveCodeBenchV6, MMLUPro, HMMT25_Nov) around the perimeter.
- **Legend**: “Data Points” (gray square = *Before Toggle*, blue circle = *After Toggle*).
- **Performance Ranges** (blue boxes):
- HMMT25_Feb: [85–95%]
- GPQADIAMOND: [80–90%]
- AIME2025: [90–100%]
- Overall: [80–90%]
- LiveCodeBenchV6: [80–90%]
- MMLUPro: [80–90%]
- HMMT25_Nov: [85–95%]
- **Change Indicators**: Green boxes (+X% = improvement) or red boxes (-X% = degradation) between *Before* and *After* points.
#### Right Chart: Token Usage
- **Axes**: Same benchmarks as the left chart.
- **Legend**: “Data Points” (gray square = *Before Toggle*, orange circle = *After Toggle*).
- **Token Ranges** (orange boxes):
- HMMT25_Feb: [20K–40K]
- GPQADIAMOND: [5K–15K]
- AIME2025: [20K–35K]
- Overall: [15K–25K]
- LiveCodeBenchV6: [20K–30K]
- MMLUPro: [1K–4K]
- HMMT25_Nov: [20K–35K]
- **Change Indicators**: Green boxes (-X = token reduction) between *Before* and *After* points.
#### Bottom Legends
- Left (Performance): *“✓ Improved: 5 | ✗ Degraded: 2”* (blue box).
- Right (Token Usage): *“✓ Reduced: 7 | ✗ Increased: 0”* (orange box).
- Overall: Green = *Improvement*, Red = *Degradation*.
### Detailed Analysis (Performance Chart)
| Benchmark | Before → After (Change) | Performance Range |
|-----------------|-------------------------|-------------------|
| HMMT25_Feb | +0.6% (improvement) | [85–95%] |
| GPQADIAMOND | -1.0% (degradation) | [80–90%] |
| AIME2025 | +1.1% (improvement) | [90–100%] |
| Overall | +0.3% (improvement) | [80–90%] |
| LiveCodeBenchV6 | +2.2% (improvement) | [80–90%] |
| MMLUPro | -2.0% (degradation) | [80–90%] |
| HMMT25_Nov | +0.8% (improvement) | [85–95%] |
### Detailed Analysis (Token Usage Chart)
| Benchmark | Before → After (Change) | Token Range |
|-----------------|-------------------------|-------------------|
| HMMT25_Feb | -7967 (reduction) | [20K–40K] |
| GPQADIAMOND | -4912 (reduction) | [5K–15K] |
| AIME2025 | -6179 (reduction) | [20K–35K] |
| Overall | -4791 (reduction) | [15K–25K] |
| LiveCodeBenchV6 | -745 (reduction) | [20K–30K] |
| MMLUPro | -817 (reduction) | [1K–4K] |
| HMMT25_Nov | -8127 (reduction) | [20K–35K] |
### Key Observations
- **Performance**: 5/7 benchmarks improved (green), 2 degraded (red: *GPQADIAMOND, MMLUPro*). Largest improvement: *LiveCodeBenchV6* (+2.2%); largest degradation: *MMLUPro* (-2.0%).
- **Token Usage**: All 7 benchmarks reduced tokens (green). Largest reduction: *HMMT25_Nov* (-8127); smallest: *LiveCodeBenchV6* (-745).
- **Correlation**: Most performance improvements align with token reductions, except *GPQADIAMOND* (performance degraded, tokens reduced) and *MMLUPro* (performance degraded, tokens reduced).
### Interpretation
The “Toggle” (configuration/model change) **improves efficiency** by reducing token usage across all benchmarks (7/7) and enhancing performance in most cases (5/7). The two performance degradations (*GPQADIAMOND, MMLUPro*) suggest the Toggle may not be optimal for all tasks, but token efficiency is consistently improved. This implies the Toggle optimizes resource usage (tokens) while maintaining or enhancing performance in most scenarios, making it a beneficial change for overall efficiency—though task-specific tuning may be needed for the two degraded benchmarks.