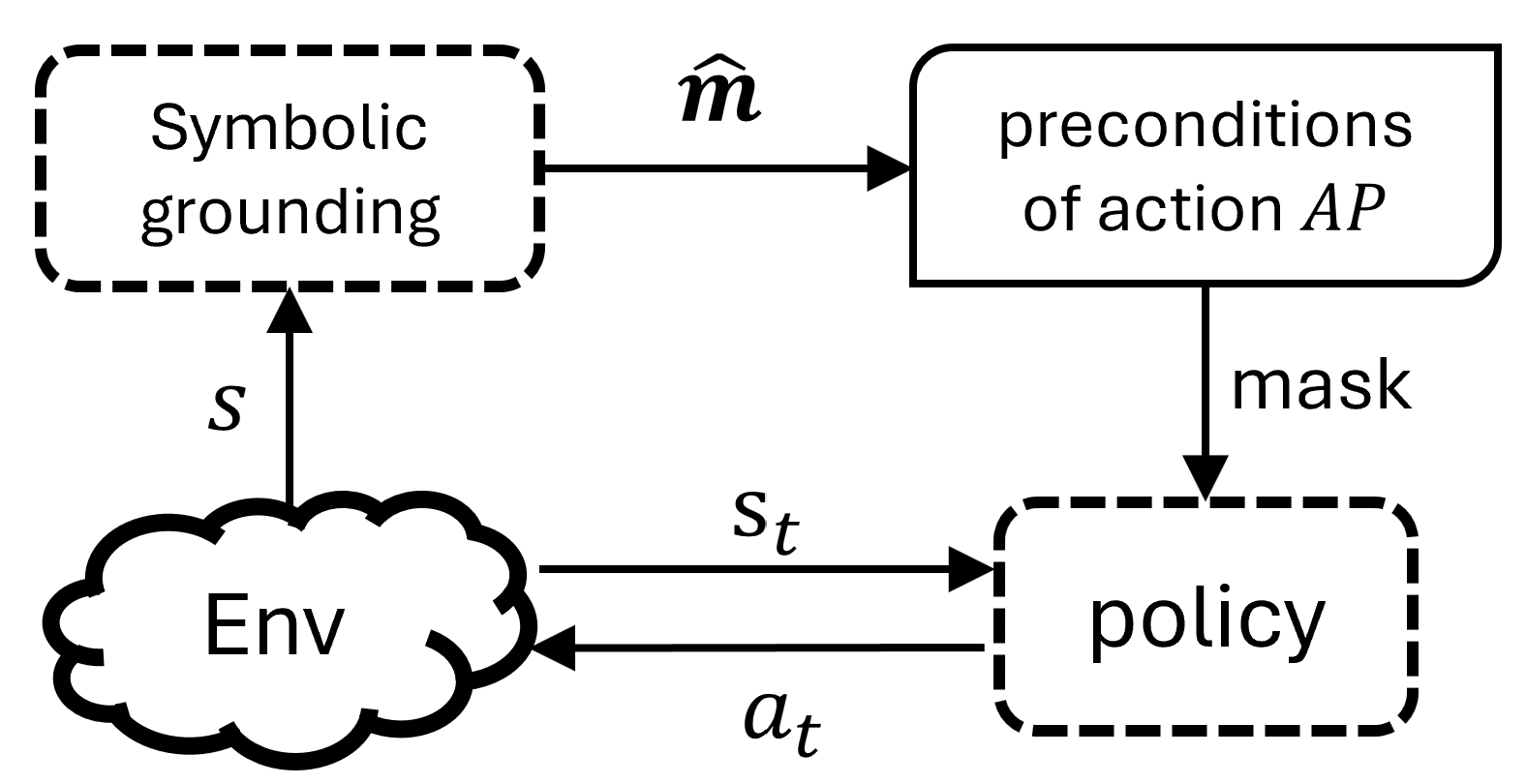
## Diagram: Symbolic Grounding and Policy Interaction
### Overview
The image is a diagram illustrating the interaction between symbolic grounding, preconditions of an action, an environment, and a policy. It depicts a flow of information and control between these components.
### Components/Axes
* **Symbolic grounding:** A dashed-line rectangle at the top-left.
* **preconditions of action AP:** A solid-line rectangle with rounded corners at the top-right.
* **Env:** A cloud-shaped object at the bottom-left.
* **policy:** A dashed-line rectangle at the bottom-right.
* **Arrows:** Indicate the direction of information flow.
* An arrow labeled "$\hat{m}$" points from "Symbolic grounding" to "preconditions of action AP".
* An arrow labeled "s" points from "Env" to "Symbolic grounding".
* An arrow labeled "mask" points from "preconditions of action AP" to "policy".
* An arrow labeled "$s_t$" points from "Env" to "policy".
* An arrow labeled "$a_t$" points from "policy" to "Env".
### Detailed Analysis or ### Content Details
The diagram shows the following relationships:
1. Symbolic grounding provides information ($\hat{m}$) to the preconditions of an action AP.
2. The environment (Env) provides state information (s) to symbolic grounding.
3. The preconditions of action AP provide a mask to the policy.
4. The environment (Env) provides state information ($s_t$) to the policy.
5. The policy outputs an action ($a_t$) that affects the environment (Env).
### Key Observations
* The diagram represents a closed-loop system.
* Symbolic grounding and preconditions of action AP are at a higher level of abstraction compared to the environment and policy.
* The policy interacts directly with the environment.
### Interpretation
The diagram illustrates a system where symbolic knowledge (grounding and preconditions) influences a policy's behavior within an environment. The symbolic grounding provides a high-level understanding of the environment, which is used to define the preconditions for actions. The policy then uses these preconditions, along with the current state of the environment, to select an action. The action, in turn, affects the environment, creating a feedback loop. The "mask" suggests that the preconditions filter or constrain the policy's actions. The diagram suggests a hierarchical control structure where symbolic reasoning guides the policy's decision-making process.