## Bar Chart: R1-Llama | AMC23
### Overview
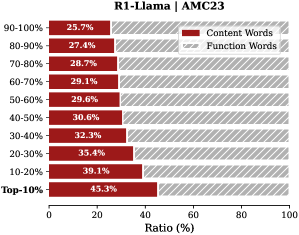
The chart compares the distribution of **Content Words** (red) and **Function Words** (gray with diagonal stripes) across 10 percentile categories (90-100% to Top-10%). Each category represents a range of ratios, with values explicitly labeled on the bars.
### Components/Axes
- **X-axis**: "Ratio (%)" (0–100), representing the percentage contribution of each word type.
- **Y-axis**: Categories labeled as percentile ranges (e.g., "90-100%", "80-90%", ..., "Top-10%").
- **Legend**:
- Red = Content Words
- Gray (diagonal stripes) = Function Words
- **Placement**: Legend is in the top-right corner. Bars are horizontal, with red bars on the left and gray bars on the right for each category.
### Detailed Analysis
- **Content Words (Red)**:
- 90-100%: 25.7%
- 80-90%: 27.4%
- 70-80%: 28.7%
- 60-70%: 29.1%
- 50-60%: 29.6%
- 40-50%: 30.6%
- 30-40%: 32.3%
- 20-30%: 35.4%
- 10-20%: 39.1%
- Top-10%: 45.3%
- **Function Words (Gray)**:
- 90-100%: 74.3% (100% - 25.7%)
- 80-90%: 72.6% (100% - 27.4%)
- 70-80%: 71.3% (100% - 28.7%)
- 60-70%: 70.9% (100% - 29.1%)
- 50-60%: 70.4% (100% - 29.6%)
- 40-50%: 69.4% (100% - 30.6%)
- 30-40%: 67.7% (100% - 32.3%)
- 20-30%: 64.6% (100% - 35.4%)
- 10-20%: 60.9% (100% - 39.1%)
- Top-10%: 54.7% (100% - 45.3%)
### Key Observations
1. **Inverse Relationship**: As the percentile category becomes more inclusive (e.g., moving from "90-100%" to "Top-10%"), the ratio of **Content Words** increases, while **Function Words** decrease.
2. **Highest Ratios**:
- Content Words peak at **45.3%** in the "Top-10%" category.
- Function Words peak at **74.3%** in the "90-100%" category.
3. **Gradual Shift**: The transition from "90-100%" to "Top-10%" shows a steady increase in Content Words (25.7% → 45.3%) and a corresponding decline in Function Words (74.3% → 54.7%).
### Interpretation
The data suggests that higher-ranked categories (e.g., "Top-10%") prioritize **Content Words** (substantive, topic-specific terms), while lower-ranked categories rely more on **Function Words** (grammatical, structural terms like "and," "the"). This could indicate that top-performing segments (e.g., in a document or dataset) are more focused on core content, whereas broader or less specific segments include more filler or structural language. The trend aligns with linguistic principles where concise, high-quality content often minimizes functional redundancy.