## Bar Chart: Math AVG vs General AVG Accuracy
### Overview
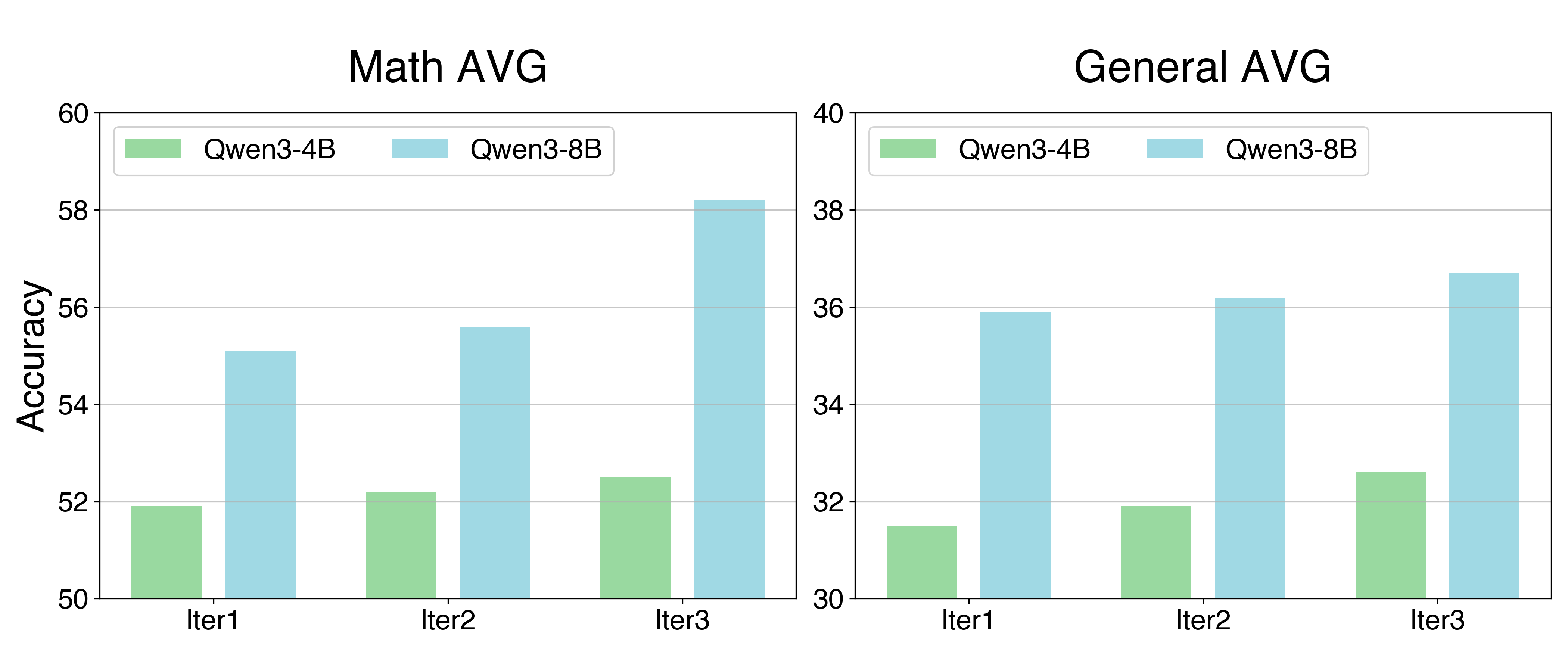
The image presents two bar charts side-by-side, comparing the accuracy of two models, "Qwen3-4B" and "Qwen3-8B", across three iterations ("Iter1", "Iter2", "Iter3"). The left chart displays "Math AVG" accuracy, while the right chart shows "General AVG" accuracy. The y-axis represents "Accuracy" with different scales for each chart.
### Components/Axes
* **Titles:**
* Left Chart: "Math AVG"
* Right Chart: "General AVG"
* **Y-axis (Accuracy):**
* Left Chart: Scale from 50 to 60, incrementing by 2.
* Right Chart: Scale from 30 to 40, incrementing by 2.
* **X-axis:** Represents iterations: "Iter1", "Iter2", "Iter3" for both charts.
* **Legend:** Located at the top of each chart.
* Green: "Qwen3-4B"
* Light Blue: "Qwen3-8B"
### Detailed Analysis
**Left Chart: Math AVG**
* **Qwen3-4B (Green):**
* Iter1: Approximately 52
* Iter2: Approximately 52.2
* Iter3: Approximately 52.5
* Trend: Slightly increasing.
* **Qwen3-8B (Light Blue):**
* Iter1: Approximately 55
* Iter2: Approximately 55.7
* Iter3: Approximately 58.2
* Trend: Increasing.
**Right Chart: General AVG**
* **Qwen3-4B (Green):**
* Iter1: Approximately 31.5
* Iter2: Approximately 32
* Iter3: Approximately 32.6
* Trend: Slightly increasing.
* **Qwen3-8B (Light Blue):**
* Iter1: Approximately 35.9
* Iter2: Approximately 36.2
* Iter3: Approximately 36.7
* Trend: Slightly increasing.
### Key Observations
* In both "Math AVG" and "General AVG", "Qwen3-8B" consistently outperforms "Qwen3-4B" across all iterations.
* The "Math AVG" accuracy is significantly higher than the "General AVG" accuracy for both models.
* The "Qwen3-8B" model shows a more pronounced increase in "Math AVG" accuracy from Iter1 to Iter3 compared to "Qwen3-4B".
* Both models show a slight increase in accuracy across iterations for both "Math AVG" and "General AVG".
### Interpretation
The data suggests that the "Qwen3-8B" model is more accurate than the "Qwen3-4B" model in both mathematical and general tasks. The higher "Math AVG" scores compared to "General AVG" scores indicate that both models perform better on mathematical problems than on general tasks. The increasing accuracy with each iteration suggests that the models are learning and improving over time. The more significant improvement of "Qwen3-8B" in "Math AVG" implies that it benefits more from iterative training in mathematical tasks compared to "Qwen3-4B". The consistent outperformance of "Qwen3-8B" suggests that the model architecture or parameters contribute to its superior performance.