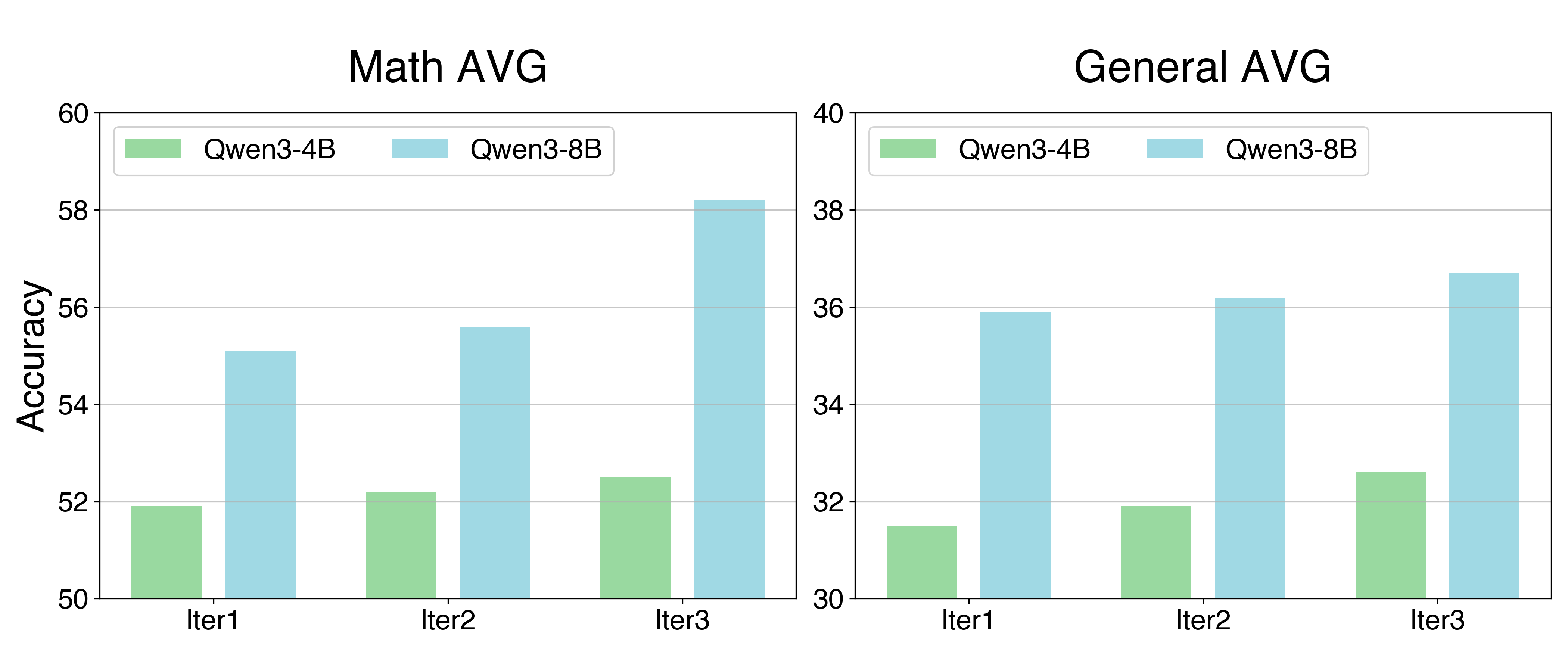
## Bar Charts: Model Accuracy Comparison (Math vs General Averages)
### Overview
The image contains two side-by-side bar charts comparing the accuracy of two AI models (Qwen3-4B and Qwen3-8B) across three iterations (Iter1, Iter2, Iter3) for two evaluation categories: Math Average and General Average. The charts use vertical bars with distinct color coding for model differentiation.
### Components/Axes
- **X-axis (Horizontal)**: Labeled "Iteration" with three categories: Iter1, Iter2, Iter3
- **Y-axis (Vertical)**: Labeled "Accuracy" with scales:
- Math AVG: 50-60 (increments of 2)
- General AVG: 30-40 (increments of 2)
- **Legends**:
- Green bars: Qwen3-4B
- Blue bars: Qwen3-8B
- **Chart Titles**:
- Left: "Math AVG"
- Right: "General AVG"
- **Bar Colors**:
- Qwen3-4B: Light green (#98df8a)
- Qwen3-8B: Light blue (#aec7e8)
### Detailed Analysis
**Math AVG Chart**:
- Iter1:
- Qwen3-4B: ~52.0 (±0.5)
- Qwen3-8B: ~55.2 (±0.5)
- Iter2:
- Qwen3-4B: ~52.5 (±0.5)
- Qwen3-8B: ~55.7 (±0.5)
- Iter3:
- Qwen3-4B: ~52.7 (±0.5)
- Qwen3-8B: ~58.2 (±0.5)
**General AVG Chart**:
- Iter1:
- Qwen3-4B: ~31.5 (±0.5)
- Qwen3-8B: ~36.0 (±0.5)
- Iter2:
- Qwen3-4B: ~32.0 (±0.5)
- Qwen3-8B: ~36.3 (±0.5)
- Iter3:
- Qwen3-4B: ~32.7 (±0.5)
- Qwen3-8B: ~36.8 (±0.5)
### Key Observations
1. **Model Performance Gap**: Qwen3-8B consistently outperforms Qwen3-4B in both categories, with a larger margin in Math AVG (3.0-6.0 points difference) than General AVG (4.0-4.5 points difference).
2. **Iteration Trends**:
- Math AVG shows a significant accuracy jump for Qwen3-8B in Iter3 (+3.0 points from Iter2)
- General AVG demonstrates steady incremental improvements across all iterations
3. **Model Size Correlation**: The 8B parameter model (Qwen3-8B) maintains higher accuracy across all iterations and categories compared to the 4B parameter model.
### Interpretation
The data suggests that larger model size (Qwen3-8B) correlates with superior performance in both mathematical reasoning and general knowledge tasks. The pronounced improvement in Math AVG during Iter3 for Qwen3-8B may indicate specialized optimization for mathematical tasks in later training iterations. The consistent performance gap across all iterations implies architectural advantages in the 8B model that persist regardless of training iteration. These findings could inform deployment decisions where computational resources allow for larger models, particularly in math-intensive applications.