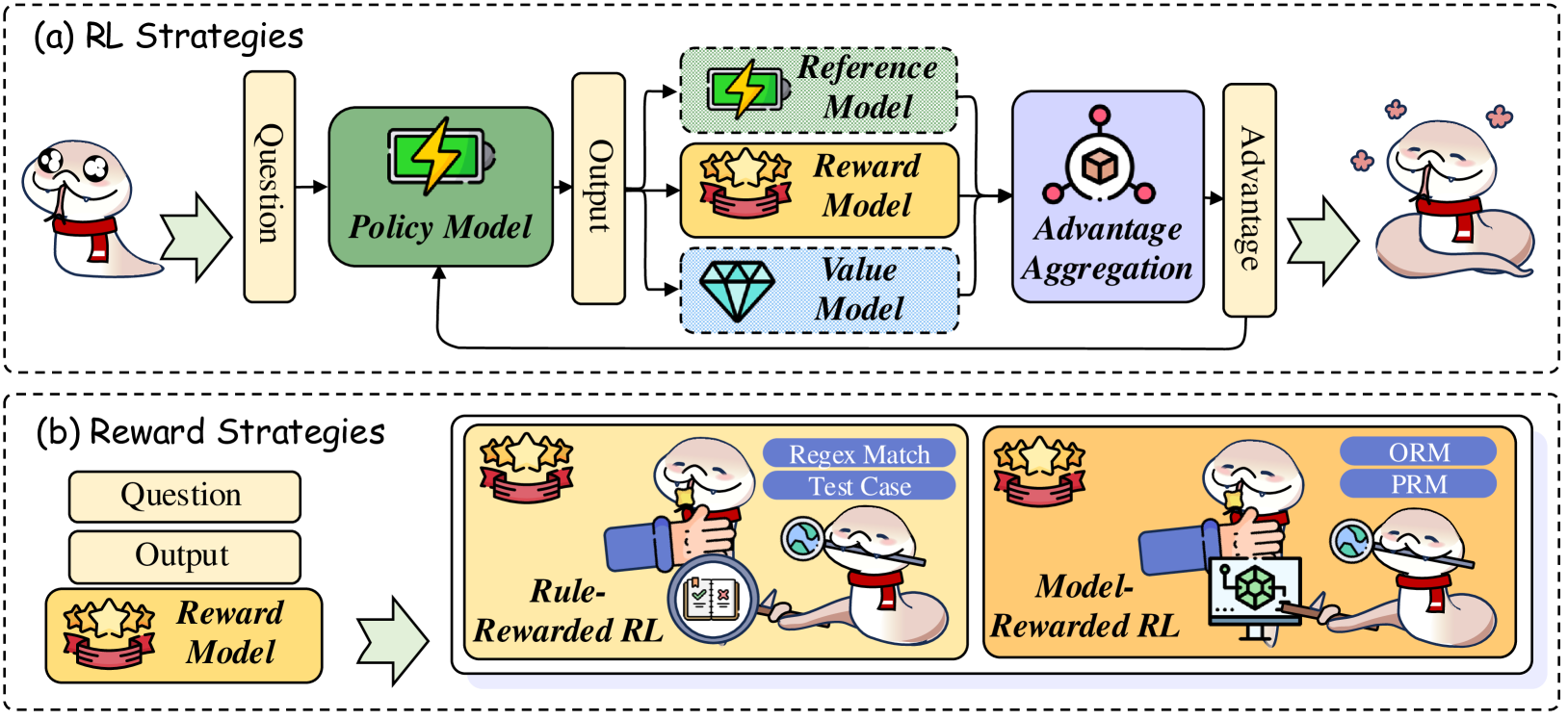
## Diagram: RL and Reward Strategies for Question Answering
### Overview
The image presents a comparative diagram illustrating two strategies for Reinforcement Learning (RL) in the context of question answering. The top section, labeled "(a) RL Strategies," depicts a standard RL pipeline. The bottom section, labeled "(b) Reward Strategies," showcases different approaches to reward shaping within an RL framework. Both sections visually represent the flow of information from a "Question" input to an "Output" and the subsequent evaluation/reward process.
### Components/Axes
The diagram is divided into two main sections: (a) and (b). Each section contains several labeled components connected by arrows indicating the flow of information.
**Section (a) - RL Strategies:**
* **Question:** Input to the system, represented by a stylized human head with a speech bubble.
* **Policy Model:** A square block with a lightning bolt symbol inside.
* **Output:** Result of the Policy Model, connected to both the Policy Model and the Reward/Value Models.
* **Reference Model:** A square block with a lightning bolt symbol.
* **Reward Model:** A diamond-shaped block.
* **Value Model:** A diamond-shaped block.
* **Advantage Aggregation:** A circular block with a diamond inside.
* **Advantage:** Output of the Advantage Aggregation, leading to a stylized human figure.
**Section (b) - Reward Strategies:**
* **Question:** Input to the system, represented by a stylized human head with a speech bubble.
* **Output:** Result of the system, connected to the Reward Model.
* **Reward Model:** A stylized treasure chest.
* **Rule-Rewarded RL:** A larger square block containing a brain icon and a computer screen displaying "Regex Match Test Case".
* **Model-Rewarded RL:** A larger square block containing a robot icon, with labels "ORM" and "PRM" near the robot's head.
### Detailed Analysis or Content Details
**Section (a) - RL Strategies:**
The flow begins with a "Question" being fed into the "Policy Model." The "Policy Model" generates an "Output." This "Output" is then used by both the "Reward Model" and the "Value Model." The "Reference Model" also influences the "Reward Model." The "Reward Model" and "Value Model" feed into "Advantage Aggregation," which produces an "Advantage" signal, ultimately influencing the system's behavior (represented by the human figure).
**Section (b) - Reward Strategies:**
The flow starts with a "Question" leading to an "Output," which is then evaluated by the "Reward Model." Two distinct reward strategies are presented: "Rule-Rewarded RL" and "Model-Rewarded RL." "Rule-Rewarded RL" utilizes a "Regex Match Test Case" for evaluation. "Model-Rewarded RL" employs "ORM" (likely representing an Output Representation Model) and "PRM" (likely representing a Prediction Representation Model) in its reward mechanism.
### Key Observations
* The diagram emphasizes the iterative nature of RL, with feedback loops influencing the policy.
* Section (b) highlights the importance of reward shaping in RL, showcasing two different approaches: rule-based and model-based.
* The visual style uses stylized icons to represent abstract concepts like "Policy," "Reward," and "Value."
* The diagram does not contain numerical data or specific values. It is a conceptual illustration of system architecture.
### Interpretation
The diagram illustrates the core components of a Reinforcement Learning system applied to question answering, and then contrasts two different strategies for defining the reward function. The first strategy (a) represents a more traditional RL approach, where a policy is learned through interaction with an environment and feedback from a reward signal. The second strategy (b) focuses on how the reward signal itself can be constructed. "Rule-Rewarded RL" suggests using predefined rules (like regular expression matching) to assess the quality of the output, while "Model-Rewarded RL" proposes leveraging other models (ORM and PRM) to provide a more nuanced reward.
The use of stylized icons suggests a high-level overview intended for an audience familiar with RL concepts. The diagram doesn't delve into the specifics of the models or algorithms used, but rather focuses on the overall architecture and the different approaches to reward design. The diagram suggests that the choice of reward strategy is a critical aspect of building effective RL systems for question answering.