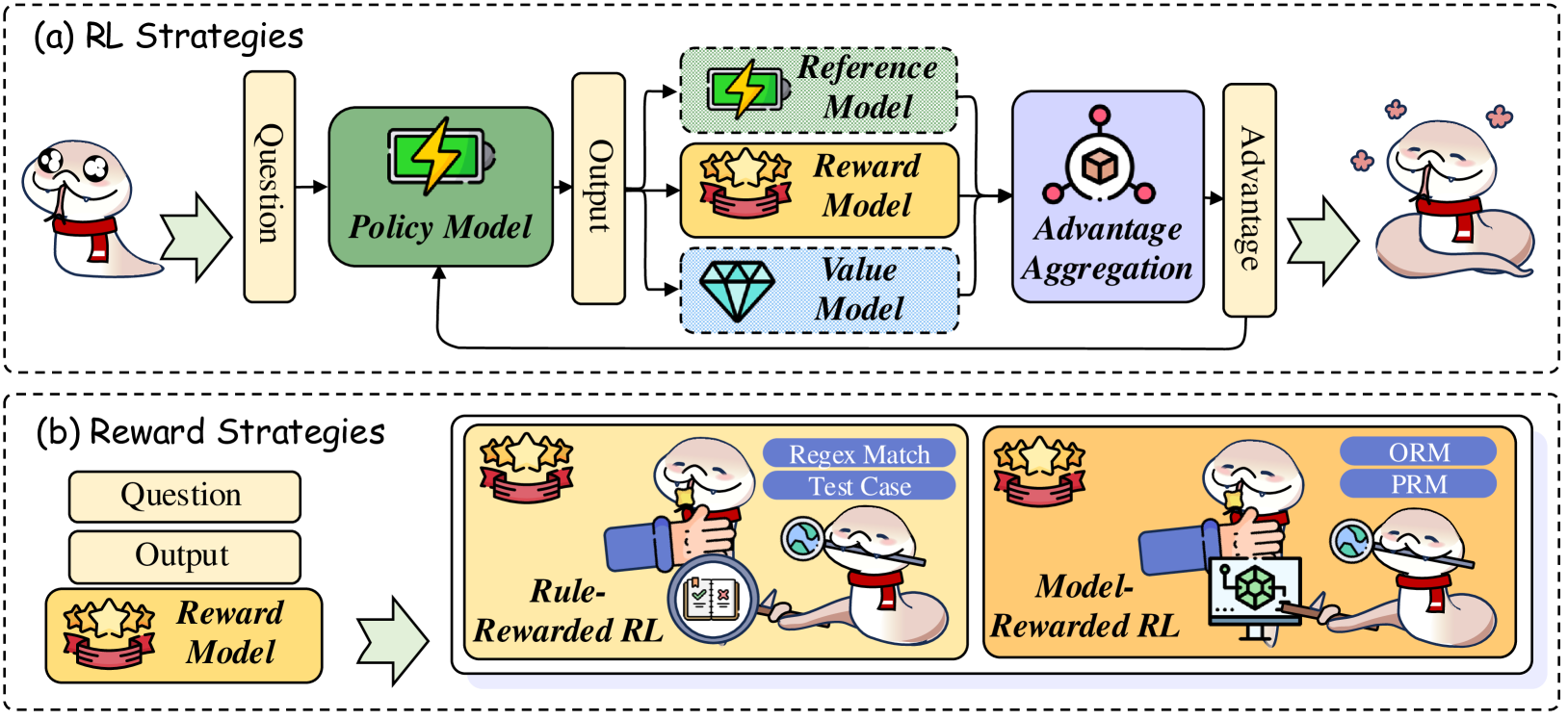
## Diagram: Reinforcement Learning Strategies and Reward Mechanisms
### Overview
The image is a two-part technical diagram illustrating components and workflows in reinforcement learning (RL) systems, specifically for language model training. It is divided into two main panels labeled (a) and (b), each enclosed in a dashed border. The diagram uses cartoonish snake characters to represent agents or processes, along with labeled boxes and icons to depict models and data flow.
### Components/Axes
The diagram is not a chart with numerical axes but a process flow diagram. Its components are:
**Panel (a): RL Strategies**
* **Input:** A cartoon snake (left) provides a "Question".
* **Core Processing Block:** A green box labeled "Policy Model" with a lightning bolt icon.
* **Output:** The Policy Model produces an "Output".
* **Evaluation Models:** The "Output" is fed into three parallel models:
1. A green-dashed box labeled "Reference Model" (lightning bolt icon).
2. A yellow box labeled "Reward Model" (star/ribbon icon).
3. A blue-dashed box labeled "Value Model" (diamond icon).
* **Aggregation:** The outputs of these three models feed into a purple box labeled "Advantage Aggregation" (cube icon).
* **Feedback Loop:** The aggregated result, labeled "Advantage", is fed back to update the "Policy Model".
* **Output:** A final cartoon snake (right) receives the result.
**Panel (b): Reward Strategies**
* **Input:** Two boxes labeled "Question" and "Output".
* **Core Component:** A yellow box labeled "Reward Model" (star/ribbon icon).
* **Two Strategy Paths:** The Reward Model's function is split into two illustrated approaches:
1. **Rule-Rewarded RL (Left, yellow background):** A snake uses a magnifying glass to inspect a document. Associated labels: "Regex Match", "Test Case".
2. **Model-Rewarded RL (Right, orange background):** A snake uses a magnifying glass to inspect a computer model. Associated labels: "ORM", "PRM".
### Detailed Analysis
**Panel (a) - RL Strategies Flow:**
1. **Trend/Flow:** The process is a closed-loop system. A question initiates the cycle, which flows left-to-right through the Policy Model to generate an output. This output is then evaluated by three distinct models (Reference, Reward, Value). Their evaluations are combined in the Advantage Aggregation module. The calculated "Advantage" signal is then used to update the Policy Model, completing the feedback loop. The final, improved output is delivered to the end-user (right snake).
2. **Component Relationships:** The Policy Model is the central actor being trained. The Reference, Reward, and Value models act as critics or evaluators. The Advantage Aggregation synthesizes their feedback into a single training signal.
**Panel (b) - Reward Strategies Breakdown:**
1. **Rule-Rewarded RL:** This approach uses deterministic, rule-based systems for evaluation. The visual metaphor shows inspection of a document. The specific methods mentioned are "Regex Match" (pattern matching in text) and "Test Case" (execution against predefined inputs/outputs).
2. **Model-Rewarded RL:** This approach uses other machine learning models for evaluation. The visual metaphor shows inspection of a computational model. The specific model types mentioned are "ORM" (Outcome Reward Model) and "PRM" (Process Reward Model).
### Key Observations
* **Visual Metaphor:** The consistent use of a cartoon snake character creates a cohesive visual narrative for the "agent" or "process" at different stages.
* **Iconography:** Each model type has a distinct icon (lightning bolt, star/ribbon, diamond, cube) for quick visual identification.
* **Color Coding:** Colors are used functionally: green for the Policy Model, yellow for the Reward Model, blue for the Value Model, and purple for the Aggregation step.
* **Spatial Layout:** Panel (a) is a horizontal, linear flow with a feedback loop. Panel (b) is a comparative layout, placing two alternative strategies side-by-side for direct contrast.
* **Language:** All text in the diagram is in English.
### Interpretation
This diagram explains a sophisticated reinforcement learning framework, likely for aligning or improving large language models (LLMs).
* **What it demonstrates:** It shows how an LLM (the Policy Model) can be iteratively improved. Instead of just comparing its output to a static dataset, it is evaluated by a suite of specialized models (Reference, Reward, Value). The "Advantage" signal likely represents how much better this output is compared to a baseline, guiding the policy update.
* **Relationship between elements:** Panel (a) defines the *architecture* of the RL training loop. Panel (b) zooms in on a critical component within that architecture—the Reward Model—and details two philosophies for implementing it: one based on hard-coded rules (deterministic, interpretable) and one based on learned models (potentially more nuanced but less transparent).
* **Notable implications:** The inclusion of both "Rule-Rewarded" and "Model-Rewarded" strategies highlights a key design choice in RL for AI: the trade-off between the precision/reliability of rules and the flexibility/generalization of learned reward models. The presence of ORM and PRM suggests a focus on evaluating not just the final answer (Outcome) but potentially the reasoning steps (Process) to generate it. This framework is characteristic of advanced techniques used to make AI systems more helpful, harmless, and accurate.