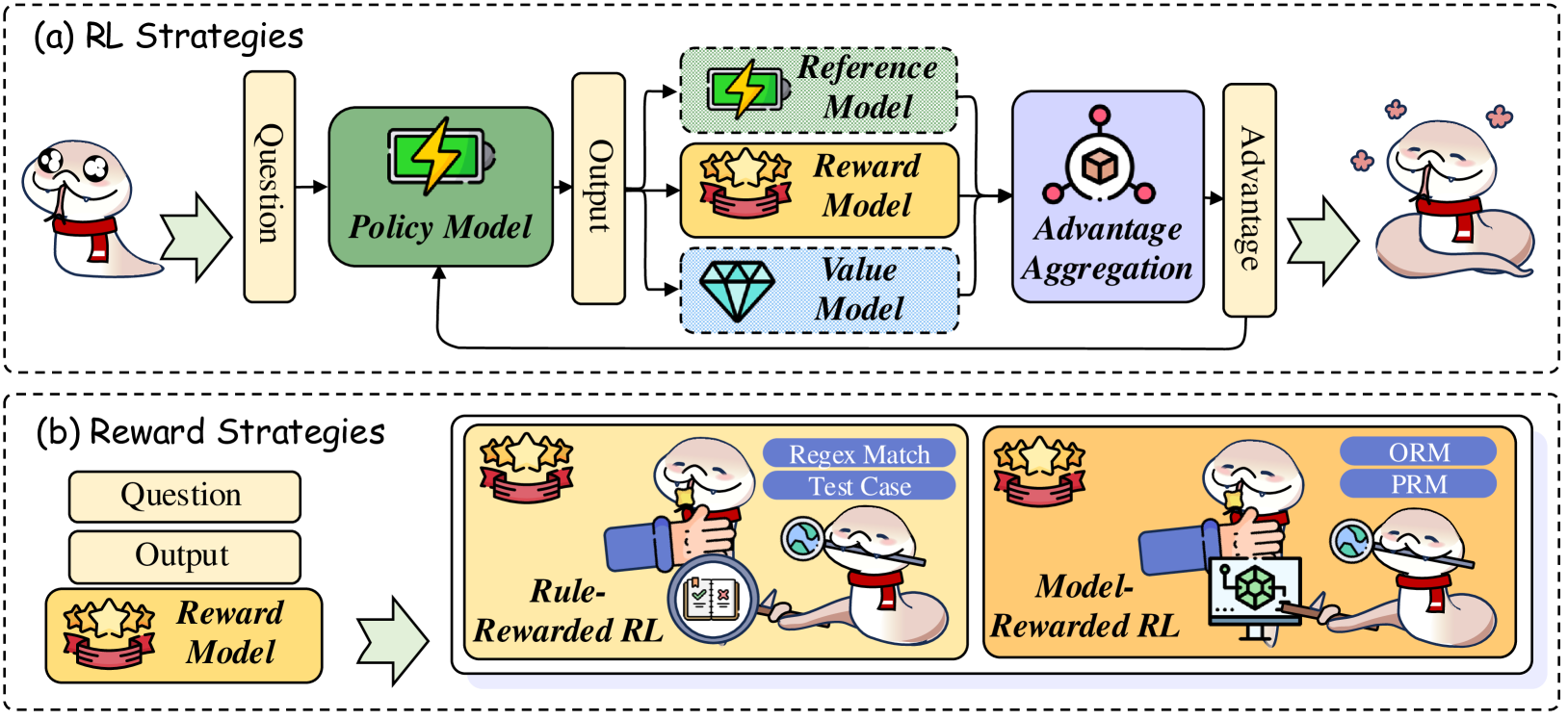
## Diagram: Reinforcement Learning (RL) and Reward Strategy Framework
### Overview
The diagram illustrates two interconnected frameworks:
1. **RL Strategies** (top section): A cyclical process involving a "Policy Model," "Reference Model," "Reward Model," "Value Model," and "Advantage Aggregation."
2. **Reward Strategies** (bottom section): Two subcategories—**Rule-Rewarded RL** and **Model-Rewarded RL**—with distinct evaluation methods (e.g., "Reflex Match Test Case," "ORM," "PRM").
### Components/Axes
#### RL Strategies (Top Section)
- **Input**:
- `Question` (text box with snake icon).
- **Core Components**:
- `Policy Model` (green box with battery icon).
- `Output` (text box).
- `Reference Model` (green box with lightning bolt).
- `Reward Model` (yellow box with stars).
- `Value Model` (blue box with diamond).
- `Advantage Aggregation` (purple box with cube icon).
- **Output**:
- `Advantage` (text box with snake icon).
- **Flow**:
- Arrows connect components in a loop: `Question → Policy Model → Output → [Reward Model, Value Model] → Advantage Aggregation → Advantage → Question`.
#### Reward Strategies (Bottom Section)
- **Subcategory 1: Rule-Rewarded RL**
- `Question` → `Output` → `Reward Model` (stars icon).
- `Reflex Match Test Case` (magnifying glass over globe).
- **Subcategory 2: Model-Rewarded RL**
- `Question` → `Output` → `Reward Model` (stars icon).
- `ORM` (On-Policy Reward Model) and `PRM` (Off-Policy Reward Model) (blue boxes with circuit/gear icons).
- **Flow**:
- Arrows connect `Question → Output → Reward Model` in both subcategories.
### Detailed Analysis
- **RL Strategies**:
- The `Policy Model` generates outputs based on input questions.
- The `Reward Model` and `Value Model` evaluate outputs, feeding into `Advantage Aggregation` to refine the policy.
- The `Reference Model` (green) likely provides benchmarking or guidance.
- **Reward Strategies**:
- **Rule-Rewarded RL** uses explicit rules (e.g., "Reflex Match Test Case") to evaluate outputs.
- **Model-Rewarded RL** employs two reward models:
- `ORM` (On-Policy): Directly tied to the policy’s actions.
- `PRM` (Off-Policy): Evaluates actions independent of the current policy.
### Key Observations
1. **Cyclical Nature**: The RL loop emphasizes continuous improvement via advantage aggregation.
2. **Divergent Reward Approaches**: Rule-based vs. model-based reward strategies suggest flexibility in evaluation criteria.
3. **Symbolism**: The snake icon (agent) and hand interactions imply human-AI collaboration.
### Interpretation
- The diagram highlights the interplay between policy optimization (RL Strategies) and reward design (Reward Strategies).
- **Rule-Rewarded RL** may prioritize predefined rules for stability, while **Model-Rewarded RL** allows adaptive evaluation via ORM/PRM.
- The absence of a legend for color coding (green/yellow/blue) leaves model roles partially ambiguous but aligns with common RL conventions (e.g., green for reference, blue for value).
- The snake’s recurring presence symbolizes the AI agent’s central role in both frameworks.
## No numerical data or trends present. Diagram focuses on conceptual relationships and component interactions.