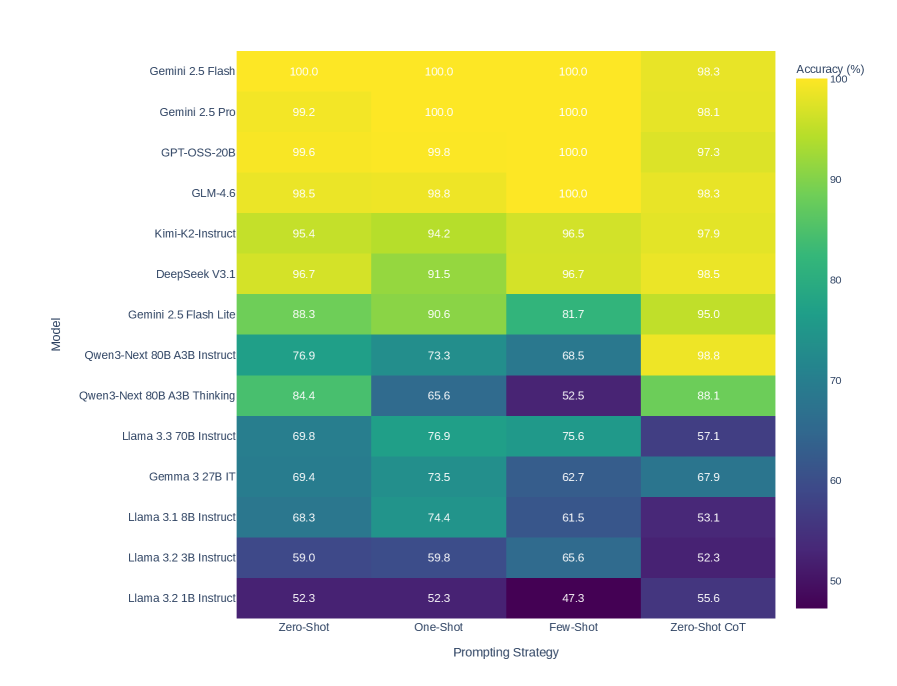
## Heatmap: AI Model Performance Across Prompting Strategies
### Overview
The image is a heatmap comparing the accuracy of various large language models (LLMs) across four prompting strategies: Zero-Shot, One-Shot, Few-Shot, and Zero-Shot Chain-of-Thought (CoT). Accuracy is represented using a color gradient from purple (low accuracy) to yellow (high accuracy), with numerical values embedded in each cell.
---
### Components/Axes
- **X-axis (Horizontal)**: Prompting Strategies
Labels: `Zero-Shot`, `One-Shot`, `Few-Shot`, `Zero-Shot CoT`
- **Y-axis (Vertical)**: AI Models
Labels (top to bottom):
`Gemini 2.5 Flash`, `Gemini 2.5 Pro`, `GPT-OSS-20B`, `GLM-4.6`, `Kimi-K2-Instruct`, `DeepSeek V3.1`, `Gemini 2.5 Flash Lite`, `Qwen3-Next 80B A3B Instruct`, `Qwen3-Next 80B A3B Thinking`, `Llama 3.33 70B Instruct`, `Gemma 3 27B IT`, `Llama 3.1 8B Instruct`, `Llama 3.2 3B Instruct`, `Llama 3.2 1B Instruct`
- **Legend**:
Color bar labeled `Accuracy (%)` ranging from **50% (purple)** to **100% (yellow)**.
---
### Detailed Analysis
#### Model Performance by Strategy
1. **Gemini 2.5 Flash**
- All strategies: **100%** (Zero-Shot, One-Shot, Few-Shot)
- Zero-Shot CoT: **98.3%**
2. **Gemini 2.5 Pro**
- All strategies: **100%** (Zero-Shot, One-Shot, Few-Shot)
- Zero-Shot CoT: **98.1%**
3. **GPT-OSS-20B**
- Zero-Shot: **99.6%**
- One-Shot: **99.8%**
- Few-Shot: **100%**
- Zero-Shot CoT: **97.3%**
4. **GLM-4.6**
- Zero-Shot: **98.5%**
- One-Shot: **98.8%**
- Few-Shot: **100%**
- Zero-Shot CoT: **98.3%**
5. **Kimi-K2-Instruct**
- Zero-Shot: **95.4%**
- One-Shot: **94.2%**
- Few-Shot: **96.5%**
- Zero-Shot CoT: **97.9%**
6. **DeepSeek V3.1**
- Zero-Shot: **96.7%**
- One-Shot: **91.5%**
- Few-Shot: **96.7%**
- Zero-Shot CoT: **98.5%**
7. **Gemini 2.5 Flash Lite**
- Zero-Shot: **88.3%**
- One-Shot: **90.6%**
- Few-Shot: **81.7%**
- Zero-Shot CoT: **95.0%**
8. **Qwen3-Next 80B A3B Instruct**
- Zero-Shot: **76.9%**
- One-Shot: **73.3%**
- Few-Shot: **68.5%**
- Zero-Shot CoT: **98.8%**
9. **Qwen3-Next 80B A3B Thinking**
- Zero-Shot: **84.4%**
- One-Shot: **65.6%**
- Few-Shot: **52.5%**
- Zero-Shot CoT: **88.1%**
10. **Llama 3.33 70B Instruct**
- Zero-Shot: **69.8%**
- One-Shot: **76.9%**
- Few-Shot: **75.6%**
- Zero-Shot CoT: **57.1%**
11. **Gemma 3 27B IT**
- Zero-Shot: **69.4%**
- One-Shot: **73.5%**
- Few-Shot: **62.7%**
- Zero-Shot CoT: **67.9%**
12. **Llama 3.1 8B Instruct**
- Zero-Shot: **68.3%**
- One-Shot: **74.4%**
- Few-Shot: **61.5%**
- Zero-Shot CoT: **53.1%**
13. **Llama 3.2 3B Instruct**
- Zero-Shot: **59.0%**
- One-Shot: **59.8%**
- Few-Shot: **65.6%**
- Zero-Shot CoT: **52.3%**
14. **Llama 3.2 1B Instruct**
- Zero-Shot: **52.3%**
- One-Shot: **52.3%**
- Few-Shot: **47.3%**
- Zero-Shot CoT: **55.6%**
---
### Key Observations
1. **Top Performers**:
- Gemini 2.5 Flash and Pro dominate all strategies with near-perfect accuracy (98–100%).
- GPT-OSS-20B and GLM-4.6 also show consistently high performance (97–100%).
2. **Llama Models Struggle**:
- Llama 3.2 1B Instruct has the lowest accuracy across all strategies (47.3–55.6%).
- Llama 3.33 70B Instruct performs poorly in Zero-Shot CoT (**57.1%**).
3. **Zero-Shot CoT Variability**:
- Some models (e.g., Qwen3-Next 80B A3B Instruct) show dramatic improvements in Zero-Shot CoT (**98.8%** vs. 76.9% in Zero-Shot).
- Others (e.g., Llama 3.2 1B Instruct) see minimal gains (**55.6%** vs. 52.3%).
4. **Color Consistency**:
- Yellow cells (high accuracy) align with Gemini, GPT-OSS, and GLM models.
- Purple cells (low accuracy) correspond to Llama 3.2 1B Instruct and Few-Shot strategies for smaller models.
---
### Interpretation
The heatmap reveals that **larger, more advanced models** (e.g., Gemini, GPT-OSS, GLM) maintain high accuracy across all prompting strategies, suggesting robustness in handling diverse inputs. In contrast, **smaller Llama models** (1B, 3.2 3B) underperform significantly, particularly in Few-Shot and Zero-Shot CoT, highlighting limitations in contextual reasoning without extensive examples.
The **Zero-Shot CoT strategy** acts as a double-edged sword: it improves performance for some models (e.g., Qwen3-Next 80B A3B Instruct) but fails to mitigate weaknesses in others (e.g., Llama 3.2 1B Instruct). This suggests that CoT prompting may require model-specific optimizations.
The data underscores the importance of model architecture and size in determining prompting strategy effectiveness, with larger models generally offering more consistent and reliable performance.