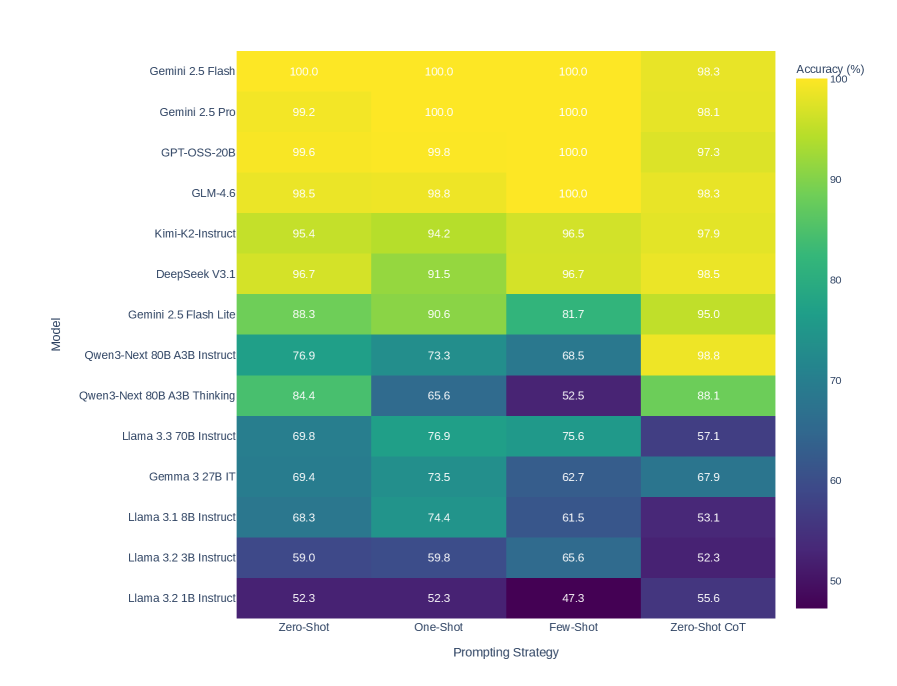
## Heatmap: Model Accuracy vs. Prompting Strategy
### Overview
The image is a heatmap showing the accuracy (%) of various language models across different prompting strategies. The models are listed on the vertical axis, and the prompting strategies are listed on the horizontal axis. The color of each cell represents the accuracy, with yellow indicating higher accuracy and dark purple indicating lower accuracy. A colorbar on the right provides a visual key for the accuracy values.
### Components/Axes
* **Vertical Axis (Model):** Lists the language models being evaluated.
* Gemini 2.5 Flash
* Gemini 2.5 Pro
* GPT-OSS-20B
* GLM-4.6
* Kimi-K2-Instruct
* DeepSeek V3.1
* Gemini 2.5 Flash Lite
* Qwen3-Next 80B A3B Instruct
* Qwen3-Next 80B A3B Thinking
* Llama 3.3 70B Instruct
* Gemma 3 27B IT
* Llama 3.1 8B Instruct
* Llama 3.2 3B Instruct
* Llama 3.2 1B Instruct
* **Horizontal Axis (Prompting Strategy):** Lists the prompting strategies used.
* Zero-Shot
* One-Shot
* Few-Shot
* Zero-Shot CoT (Chain-of-Thought)
* **Colorbar (Accuracy %):** A vertical colorbar on the right side of the heatmap indicates the accuracy percentage, ranging from 50% (dark purple) to 100% (yellow). The colorbar has tick marks at 50, 60, 70, 80, 90, and 100.
### Detailed Analysis or ### Content Details
The heatmap displays the accuracy of different models under different prompting strategies. The values are as follows:
| Model | Zero-Shot | One-Shot | Few-Shot | Zero-Shot CoT |
| --------------------------- | --------- | -------- | -------- | ------------- |
| Gemini 2.5 Flash | 100.0 | 100.0 | 100.0 | 98.3 |
| Gemini 2.5 Pro | 99.2 | 100.0 | 100.0 | 98.1 |
| GPT-OSS-20B | 99.6 | 99.8 | 100.0 | 97.3 |
| GLM-4.6 | 98.5 | 98.8 | 100.0 | 98.3 |
| Kimi-K2-Instruct | 95.4 | 94.2 | 96.5 | 97.9 |
| DeepSeek V3.1 | 96.7 | 91.5 | 96.7 | 98.5 |
| Gemini 2.5 Flash Lite | 88.3 | 90.6 | 81.7 | 95.0 |
| Qwen3-Next 80B A3B Instruct | 76.9 | 73.3 | 68.5 | 98.8 |
| Qwen3-Next 80B A3B Thinking | 84.4 | 65.6 | 52.5 | 88.1 |
| Llama 3.3 70B Instruct | 69.8 | 76.9 | 75.6 | 57.1 |
| Gemma 3 27B IT | 69.4 | 73.5 | 62.7 | 67.9 |
| Llama 3.1 8B Instruct | 68.3 | 74.4 | 61.5 | 53.1 |
| Llama 3.2 3B Instruct | 59.0 | 59.8 | 65.6 | 52.3 |
| Llama 3.2 1B Instruct | 52.3 | 52.3 | 47.3 | 55.6 |
### Key Observations
* The top models (Gemini 2.5 Flash, Gemini 2.5 Pro, GPT-OSS-20B, GLM-4.6) generally achieve high accuracy (close to 100%) across all prompting strategies.
* The "Zero-Shot CoT" prompting strategy appears to be particularly effective for Qwen3-Next 80B A3B Instruct, resulting in an accuracy of 98.8%.
* The Llama models (3.3 70B Instruct, 3.1 8B Instruct, 3.2 3B Instruct, 3.2 1B Instruct) generally have lower accuracy compared to the other models, especially with the "Zero-Shot CoT" prompting strategy.
* The performance of Qwen3-Next 80B A3B Thinking varies significantly across prompting strategies, with the lowest accuracy (52.5%) observed for "Few-Shot" prompting.
### Interpretation
The heatmap provides a comparative analysis of language model performance under different prompting strategies. The data suggests that:
* Some models (e.g., Gemini 2.5 Flash, Gemini 2.5 Pro) are highly robust and achieve near-perfect accuracy regardless of the prompting strategy used.
* The choice of prompting strategy can significantly impact the performance of certain models. For example, the "Zero-Shot CoT" strategy seems to benefit Qwen3-Next 80B A3B Instruct but not the Llama models.
* Smaller models (e.g., Llama 3.2 1B Instruct) generally exhibit lower accuracy compared to larger models, indicating a correlation between model size and performance.
* The "Few-Shot" prompting strategy appears to be the least effective for Qwen3-Next 80B A3B Thinking, suggesting that this model may struggle with learning from a limited number of examples.
The heatmap highlights the importance of selecting an appropriate prompting strategy for a given language model to maximize its accuracy and effectiveness. It also demonstrates the performance differences between various models, providing valuable insights for model selection and optimization.