\n
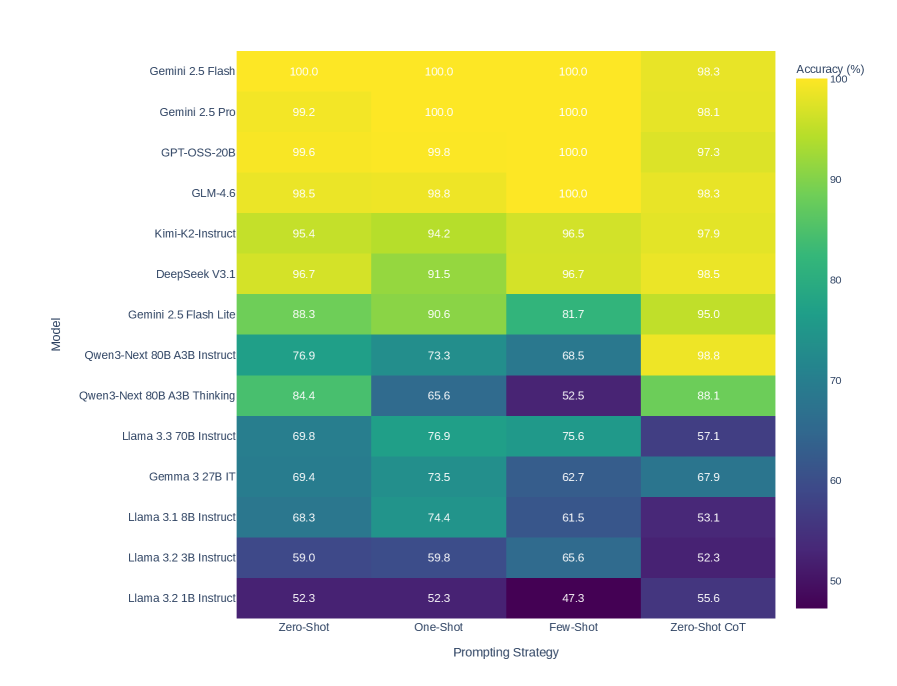
## Heatmap: Model Accuracy vs. Prompting Strategy
### Overview
This image presents a heatmap comparing the accuracy of various language models across four different prompting strategies. The heatmap uses a color gradient to represent accuracy, ranging from purple (lower accuracy) to yellow (higher accuracy). The Y-axis lists the models, and the X-axis represents the prompting strategies.
### Components/Axes
* **Y-axis (Vertical):** "Model" - Lists the following language models:
* Gemini 2.5 Flash
* Gemini 2.5 Pro
* GPT-OSS-20B
* GLM-4.6
* Kimi-K2-Instruct
* DeepSeek V3.1
* Gemini 2.5 Flash Lite
* Qwen3-Next 80B A3B Instruct
* Qwen3-Next 80B A3B Thinking
* Llama 3.3 70B Instruct
* Gemma 3.2 7B IT
* Llama 3.1 8B Instruct
* Llama 3.2 3B Instruct
* Llama 3.2 1B Instruct
* **X-axis (Horizontal):** "Prompting Strategy" - Lists the following strategies:
* Zero-Shot
* One-Shot
* Few-Shot
* Zero-Shot CoT
* **Color Scale (Right):** "Accuracy (%)" - A gradient from purple to yellow, indicating accuracy levels from approximately 50% to 100%.
* **Data Cells:** Each cell represents the accuracy of a specific model using a specific prompting strategy. The accuracy is displayed as a numerical value within each cell.
### Detailed Analysis
The heatmap displays accuracy percentages for each model and prompting strategy combination. Here's a breakdown of the data, reading left to right across the prompting strategies:
* **Zero-Shot:**
* Gemini 2.5 Flash: 100.0%
* Gemini 2.5 Pro: 99.2%
* GPT-OSS-20B: 99.6%
* GLM-4.6: 98.5%
* Kimi-K2-Instruct: 95.4%
* DeepSeek V3.1: 96.7%
* Gemini 2.5 Flash Lite: 88.3%
* Qwen3-Next 80B A3B Instruct: 76.9%
* Qwen3-Next 80B A3B Thinking: 84.4%
* Llama 3.3 70B Instruct: 69.8%
* Gemma 3.2 7B IT: 69.4%
* Llama 3.1 8B Instruct: 68.3%
* Llama 3.2 3B Instruct: 59.0%
* Llama 3.2 1B Instruct: 52.3%
* **One-Shot:**
* Gemini 2.5 Flash: 100.0%
* Gemini 2.5 Pro: 100.0%
* GPT-OSS-20B: 99.8%
* GLM-4.6: 98.8%
* Kimi-K2-Instruct: 94.2%
* DeepSeek V3.1: 91.5%
* Gemini 2.5 Flash Lite: 90.6%
* Qwen3-Next 80B A3B Instruct: 73.3%
* Qwen3-Next 80B A3B Thinking: 65.6%
* Llama 3.3 70B Instruct: 76.9%
* Gemma 3.2 7B IT: 73.5%
* Llama 3.1 8B Instruct: 74.4%
* Llama 3.2 3B Instruct: 59.8%
* Llama 3.2 1B Instruct: 52.3%
* **Few-Shot:**
* Gemini 2.5 Flash: 100.0%
* Gemini 2.5 Pro: 100.0%
* GPT-OSS-20B: 100.0%
* GLM-4.6: 100.0%
* Kimi-K2-Instruct: 96.5%
* DeepSeek V3.1: 96.7%
* Gemini 2.5 Flash Lite: 81.7%
* Qwen3-Next 80B A3B Instruct: 68.5%
* Qwen3-Next 80B A3B Thinking: 52.5%
* Llama 3.3 70B Instruct: 75.6%
* Gemma 3.2 7B IT: 62.7%
* Llama 3.1 8B Instruct: 61.5%
* Llama 3.2 3B Instruct: 65.6%
* Llama 3.2 1B Instruct: 47.3%
* **Zero-Shot CoT:**
* Gemini 2.5 Flash: 98.3%
* Gemini 2.5 Pro: 98.1%
* GPT-OSS-20B: 97.3%
* GLM-4.6: 98.3%
* Kimi-K2-Instruct: 97.9%
* DeepSeek V3.1: 98.5%
* Gemini 2.5 Flash Lite: 95.0%
* Qwen3-Next 80B A3B Instruct: 98.8%
* Qwen3-Next 80B A3B Thinking: 88.1%
* Llama 3.3 70B Instruct: 57.1%
* Gemma 3.2 7B IT: 67.9%
* Llama 3.1 8B Instruct: 53.1%
* Llama 3.2 3B Instruct: 52.3%
* Llama 3.2 1B Instruct: 55.6%
### Key Observations
* **High Performers:** Gemini 2.5 Flash, Gemini 2.5 Pro, and GPT-OSS-20B consistently achieve the highest accuracy scores (often 100%) across all prompting strategies.
* **Prompting Strategy Impact:** Accuracy generally increases with more sophisticated prompting strategies (Zero-Shot < One-Shot < Few-Shot). However, Zero-Shot CoT often performs similarly to or slightly below Few-Shot.
* **Model Size Matters:** Smaller models (Llama 3.2 1B Instruct, Llama 3.2 3B Instruct) consistently exhibit lower accuracy scores compared to larger models.
* **Qwen3-Next 80B A3B Thinking:** This model shows a significant drop in accuracy when moving from One-Shot to Few-Shot prompting.
* **Llama 3.3 70B Instruct:** This model shows a significant drop in accuracy when moving from One-Shot to Zero-Shot CoT prompting.
### Interpretation
The heatmap demonstrates a clear correlation between model size, prompting strategy, and accuracy. Larger models generally outperform smaller models, and more complex prompting strategies tend to yield higher accuracy. The consistent high performance of Gemini 2.5 Flash, Gemini 2.5 Pro, and GPT-OSS-20B suggests these models are particularly robust and capable of effectively utilizing different prompting techniques.
The variations in performance across prompting strategies highlight the importance of prompt engineering. While simply providing more examples (Few-Shot) often improves accuracy, the effectiveness of Chain-of-Thought (CoT) prompting appears to be model-dependent. The drop in accuracy for Qwen3-Next 80B A3B Thinking with Few-Shot suggests that this model may not benefit as much from additional examples, or that the examples need to be carefully curated.
The heatmap provides valuable insights for selecting the appropriate model and prompting strategy for a given task. It also underscores the ongoing need for research into more effective prompting techniques and the development of larger, more capable language models. The data suggests that the models are not uniformly sensitive to prompting strategies, and a one-size-fits-all approach is unlikely to be optimal.