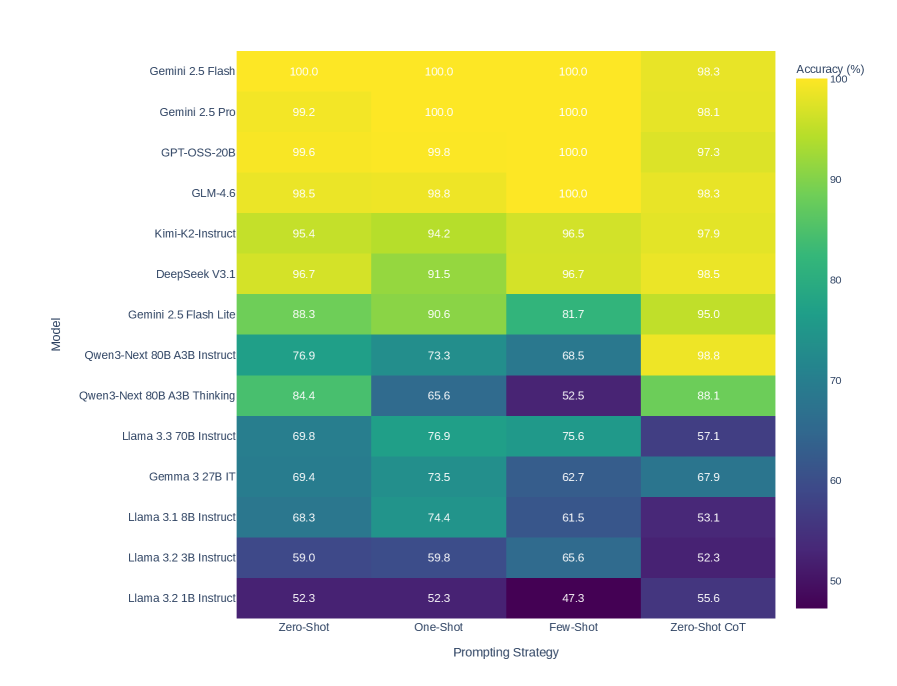
## Heatmap: AI Model Accuracy Across Prompting Strategies
### Overview
This image is a heatmap chart comparing the performance of 13 different large language models (LLMs) across four distinct prompting strategies. The performance metric is accuracy, presented as a percentage. The chart uses a color gradient from dark purple (low accuracy, ~50%) to bright yellow (high accuracy, 100%) to visually represent the data.
### Components/Axes
* **Y-Axis (Vertical):** Labeled "Model". It lists 13 AI models from top to bottom.
* Gemini 2.5 Flash
* Gemini 2.5 Pro
* GPT-OSS-20B
* GLM-4.6
* Kimi-K2-Instruct
* DeepSeek V3.1
* Gemini 2.5 Flash Lite
* Qwen3-Next 80B A3B Instruct
* Qwen3-Next 80B A3B Thinking
* Llama 3.3 70B Instruct
* Gemma 3 27B IT
* Llama 3.1 8B Instruct
* Llama 3.2 3B Instruct
* Llama 3.2 1B Instruct
* **X-Axis (Horizontal):** Labeled "Prompting Strategy". It lists four strategies from left to right.
* Zero-Shot
* One-Shot
* Few-Shot
* Zero-Shot CoT (Chain-of-Thought)
* **Legend/Color Scale:** Located on the right side, labeled "Accuracy (%)". It is a vertical color bar with numerical markers at 50, 60, 70, 80, 90, and 100. The gradient runs from dark purple at 50% to bright yellow at 100%.
### Detailed Analysis
The following table reconstructs the accuracy data from the heatmap. Values are read directly from the cells.
| Model | Zero-Shot | One-Shot | Few-Shot | Zero-Shot CoT |
| :--- | :--- | :--- | :--- | :--- |
| **Gemini 2.5 Flash** | 100.0 | 100.0 | 100.0 | 98.3 |
| **Gemini 2.5 Pro** | 99.2 | 100.0 | 100.0 | 98.1 |
| **GPT-OSS-20B** | 99.6 | 99.8 | 100.0 | 97.3 |
| **GLM-4.6** | 98.5 | 98.8 | 100.0 | 98.3 |
| **Kimi-K2-Instruct** | 95.4 | 94.2 | 96.5 | 97.9 |
| **DeepSeek V3.1** | 96.7 | 91.5 | 96.7 | 98.5 |
| **Gemini 2.5 Flash Lite** | 88.3 | 90.6 | 81.7 | 95.0 |
| **Qwen3-Next 80B A3B Instruct** | 76.9 | 73.3 | 68.5 | 98.8 |
| **Qwen3-Next 80B A3B Thinking** | 84.4 | 65.6 | 52.5 | 88.1 |
| **Llama 3.3 70B Instruct** | 69.8 | 76.9 | 75.6 | 57.1 |
| **Gemma 3 27B IT** | 69.4 | 73.5 | 62.7 | 67.9 |
| **Llama 3.1 8B Instruct** | 68.3 | 74.4 | 61.5 | 53.1 |
| **Llama 3.2 3B Instruct** | 59.0 | 59.8 | 65.6 | 52.3 |
| **Llama 3.2 1B Instruct** | 52.3 | 52.3 | 47.3 | 55.6 |
**Trend Verification by Model (Visual Description):**
* **Top Tier (Gemini 2.5 Flash/Pro, GPT-OSS-20B, GLM-4.6):** These models show consistently high accuracy (bright yellow) across all strategies, with values near or at 100%. Their performance is stable, with only minor dips in the "Zero-Shot CoT" column for some.
* **Mid Tier (Kimi-K2, DeepSeek V3.1, Gemini 2.5 Flash Lite):** These models display a mix of yellow and green cells. DeepSeek V3.1 shows a notable dip in "One-Shot" (91.5) but recovers in other strategies. Gemini 2.5 Flash Lite has its lowest score in "Few-Shot" (81.7).
* **Variable Performance (Qwen3-Next models):** The "Instruct" variant shows a clear downward trend from left to right (76.9 -> 73.3 -> 68.5) before a dramatic spike to 98.8 in "Zero-Shot CoT". The "Thinking" variant shows a steep decline to a low of 52.5 in "Few-Shot" before recovering to 88.1.
* **Lower Tier (Llama & Gemma models):** These models are represented by green, blue, and purple cells, indicating lower accuracy. Most show a pattern of moderate performance in "One-Shot" or "Few-Shot" but a significant drop in "Zero-Shot CoT", with the exception of the smallest Llama 3.2 1B model.
### Key Observations
1. **Dominant Models:** Gemini 2.5 Flash and Gemini 2.5 Pro achieve perfect or near-perfect scores (100.0, 99.2) in multiple strategies.
2. **Strategy Impact:** The "Zero-Shot CoT" strategy has a polarizing effect. It boosts the accuracy of the Qwen3-Next 80B A3B Instruct model to 98.8 (from 68.5 in Few-Shot) but severely degrades the performance of several Llama models (e.g., Llama 3.3 70B drops to 57.1).
3. **Performance Floor:** The lowest accuracy recorded is 47.3% for Llama 3.2 1B Instruct using the "Few-Shot" strategy.
4. **Model Size Correlation:** There is a general, though not perfect, correlation between model size/name and performance. The larger, more advanced models (Gemini 2.5, GPT-OSS, GLM) occupy the top rows with yellow cells, while smaller models (Llama 3.2 1B/3B) are at the bottom with cooler colors.
### Interpretation
This heatmap provides a comparative snapshot of LLM capabilities on a specific (but unnamed) task or benchmark. The data suggests several key insights:
* **Model Superiority:** The Gemini 2.5 series (Flash and Pro) demonstrates exceptional and robust performance, maintaining near-perfect accuracy regardless of the prompting method. This indicates strong underlying capability and less sensitivity to prompt engineering for this task.
* **Prompting Strategy is Not One-Size-Fits-All:** The effectiveness of a prompting strategy is highly model-dependent. While "Zero-Shot CoT" is a powerful technique for unlocking the reasoning potential of the Qwen3-Next Instruct model, it appears to confuse or hinder the Llama 3.x Instruct models on this task. This highlights the critical need for model-specific evaluation.
* **The "Thinking" Variant's Volatility:** The Qwen3-Next 80B A3B Thinking model shows the most dramatic variance, with accuracy swinging from 84.4% to 52.5% and back to 88.1%. This suggests its "thinking" process may be highly specialized or unstable across different prompt contexts.
* **Task Complexity Inference:** The fact that even the smallest model (Llama 3.2 1B) achieves over 50% accuracy in most strategies suggests the underlying task may not be extremely difficult, or it may be a task where memorization plays a role. However, the perfect scores of the top models indicate a clear performance ceiling exists.
In summary, the chart is a tool for benchmarking, showing that raw model size and architecture interact in complex ways with prompting techniques to determine final accuracy. It argues for empirical testing when selecting a model and prompt strategy for a specific application.