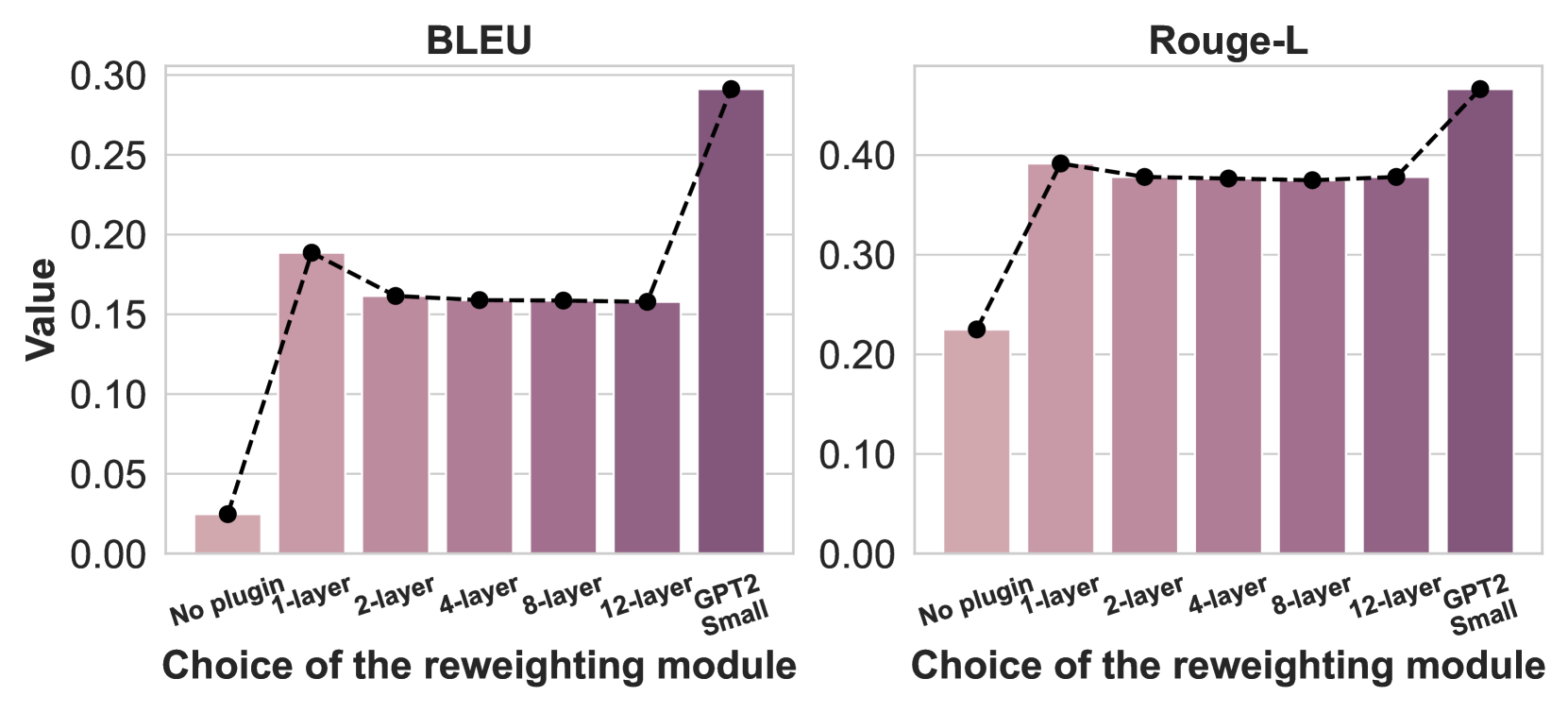
# Technical Data Extraction: Performance Comparison of Reweighting Modules
This document contains a detailed extraction of data from two side-by-side bar charts comparing the performance of different reweighting modules across two metrics: **BLEU** and **Rouge-L**.
## 1. General Layout and Metadata
- **Image Type:** Comparative Bar Charts with overlaid line plots.
- **Language:** English.
- **X-Axis Label (Both Charts):** "Choice of the reweighting module"
- **Y-Axis Label (Left Chart):** "Value"
- **X-Axis Categories (Common to both):**
1. No plugin
2. 1-layer
3. 2-layer
4. 4-layer
5. 8-layer
6. 12-layer
7. GPT2 Small
- **Visual Encoding:**
- Bars represent the value for each category.
- A dashed black line with circular markers connects the top of each bar to visualize the trend across configurations.
- Color Gradient: The bars transition from a light dusty rose (left) to a deep plum/purple (right).
---
## 2. Chart 1: BLEU Score Analysis
### Component Isolation: BLEU
- **Y-Axis Scale:** 0.00 to 0.30 with increments of 0.05.
- **Trend Description:** There is a sharp initial increase from "No plugin" to "1-layer," followed by a slight plateau/minor decrease through the "12-layer" configuration. A significant final spike occurs for the "GPT2 Small" module, which achieves the highest performance.
### Data Points (Estimated from Y-Axis)
| Reweighting Module | BLEU Value (Approx.) | Visual Trend |
| :--- | :--- | :--- |
| No plugin | 0.025 | Baseline |
| 1-layer | 0.188 | Sharp Increase |
| 2-layer | 0.162 | Slight Decrease |
| 4-layer | 0.160 | Plateau |
| 8-layer | 0.159 | Plateau |
| 12-layer | 0.158 | Plateau |
| GPT2 Small | 0.292 | Significant Spike (Peak) |
---
## 3. Chart 2: Rouge-L Score Analysis
### Component Isolation: Rouge-L
- **Y-Axis Scale:** 0.00 to 0.40+ (Markers go up to 0.45+) with increments of 0.10.
- **Trend Description:** Similar to the BLEU chart, there is a massive jump from "No plugin" to "1-layer." The performance remains remarkably stable (flat) across the "1-layer" to "12-layer" range, before another notable increase for the "GPT2 Small" module.
### Data Points (Estimated from Y-Axis)
| Reweighting Module | Rouge-L Value (Approx.) | Visual Trend |
| :--- | :--- | :--- |
| No plugin | 0.225 | Baseline |
| 1-layer | 0.392 | Sharp Increase |
| 2-layer | 0.380 | Minor Dip / Stable |
| 4-layer | 0.378 | Stable |
| 8-layer | 0.376 | Stable |
| 12-layer | 0.378 | Stable |
| GPT2 Small | 0.465 | Significant Spike (Peak) |
---
## 4. Summary of Findings
- **Impact of Plugin:** Adding any reweighting module (even a 1-layer version) provides a substantial performance boost over the "No plugin" baseline in both metrics.
- **Layer Scaling:** Increasing the number of layers in the reweighting module from 1 to 12 does not result in performance gains; in fact, performance remains largely stagnant or slightly regresses compared to the 1-layer version.
- **Model Superiority:** The "GPT2 Small" module consistently outperforms all other configurations, including the multi-layer custom modules, suggesting that the pre-trained architecture provides a superior basis for reweighting.