\n
## Diagram: Recurrent Neural Network with Attention Mechanism
### Overview
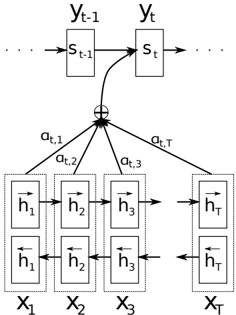
The image depicts a diagram of a recurrent neural network (RNN) architecture incorporating an attention mechanism. The diagram illustrates how the RNN processes input sequences (X1 to XT) and generates output sequences (yt-1 to yt) while selectively focusing on different parts of the input sequence using attention weights (αt,1 to αt,T).
### Components/Axes
The diagram consists of the following components:
* **Input Sequence:** Represented by X1, X2, X3,...XT at the bottom of the diagram.
* **Hidden States:** Represented by h1, h2, h3,...hT within rectangular boxes, both forward and backward passes are shown.
* **RNN Cells:** The rectangular boxes containing h1, h2, h3,...hT represent the RNN cells processing the input sequence.
* **State Vector:** Represented by st-1 and st, indicating the hidden state of the RNN at time step t-1 and t, respectively.
* **Output Sequence:** Represented by yt-1 and yt, indicating the output of the RNN at time step t-1 and t, respectively.
* **Attention Weights:** Represented by αt,1, αt,2, αt,3,...αt,T, indicating the attention weights assigned to each input element at time step t.
* **Addition Symbol:** A circled plus sign (+) represents the weighted sum of the hidden states based on the attention weights.
* **Arrows:** Arrows indicate the flow of information between the components.
### Detailed Analysis or Content Details
The diagram shows the following flow of information:
1. **Input Processing:** The input sequence X1 to XT is fed into the RNN cells. Each cell processes the input and generates a hidden state (h1 to hT).
2. **Bidirectional RNN:** Each input element X_i is processed by both a forward and backward RNN, resulting in two hidden states (h_i and h_i with an arrow pointing backwards).
3. **State Update:** The hidden state st is updated based on the previous hidden state st-1 and the current input yt.
4. **Attention Weight Calculation:** Attention weights αt,1 to αt,T are calculated based on the hidden states h1 to hT and the current state st.
5. **Context Vector Creation:** A context vector is created by taking a weighted sum of the hidden states h1 to hT, using the attention weights αt,1 to αt,T. The addition symbol (+) indicates this weighted sum.
6. **Output Generation:** The context vector is then used to generate the output yt.
The diagram does not provide specific numerical values for the hidden states, attention weights, or outputs. It is a conceptual illustration of the architecture.
### Key Observations
* The attention mechanism allows the RNN to focus on different parts of the input sequence when generating the output.
* The bidirectional RNN processes the input sequence in both forward and backward directions, capturing more contextual information.
* The diagram highlights the key components and flow of information in an RNN with attention.
### Interpretation
The diagram illustrates a powerful technique for sequence modeling, where the attention mechanism allows the model to selectively focus on relevant parts of the input sequence. This is particularly useful for tasks such as machine translation, image captioning, and speech recognition, where the relationship between the input and output sequences is not always straightforward. The bidirectional RNN further enhances the model's ability to capture contextual information by processing the input sequence in both directions. The diagram provides a clear and concise representation of this complex architecture, making it easier to understand the underlying principles and how the different components interact with each other. The absence of numerical data suggests this is a conceptual illustration rather than a presentation of experimental results. The diagram is a high-level overview and does not delve into the specifics of how the attention weights are calculated or how the hidden states are updated.