\n
## Pie Charts: Errors GPT-4o and Claude Opus (Search and Read w/o Demo)
### Overview
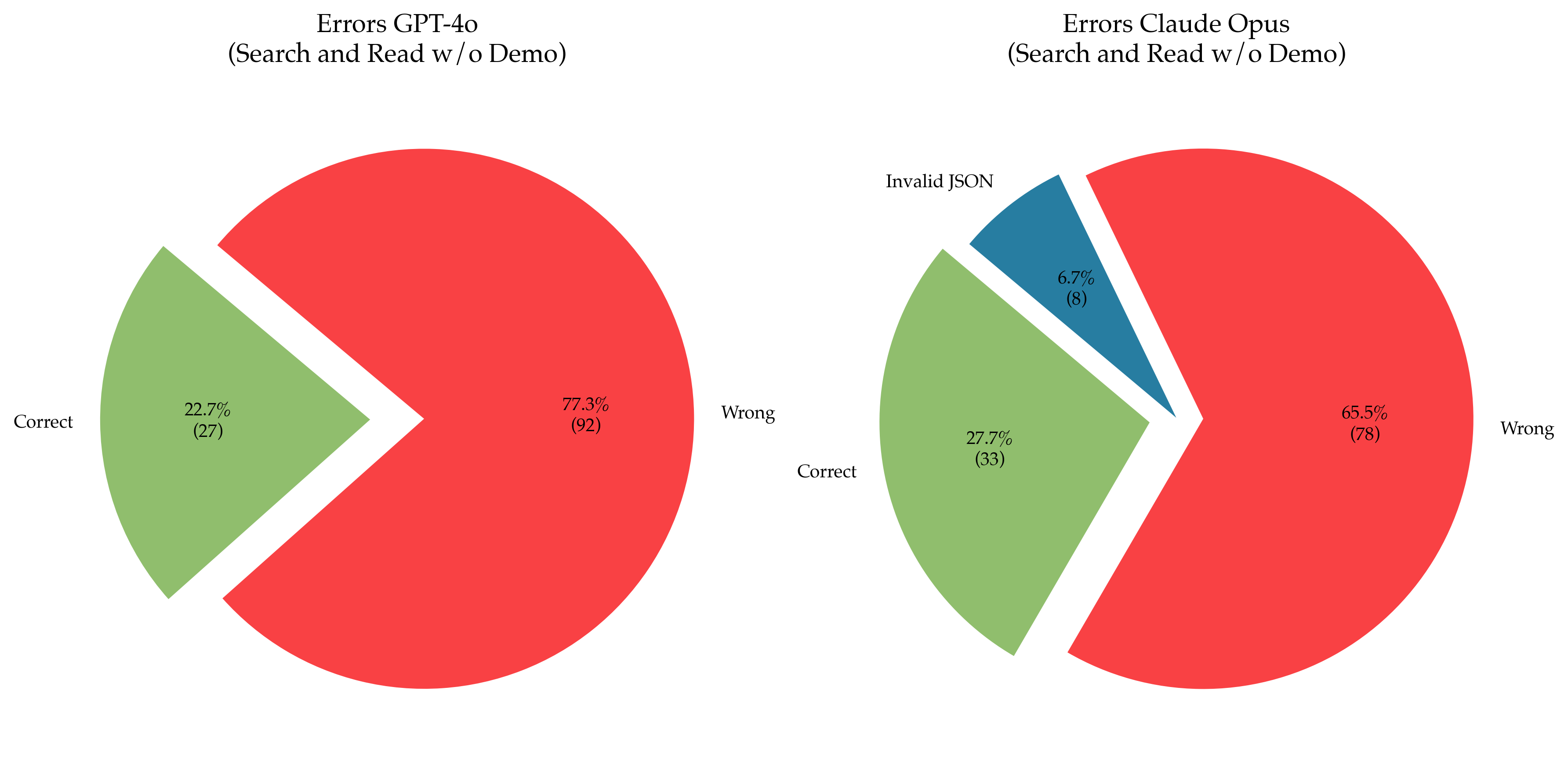
The image presents two pie charts side-by-side, comparing the error rates of GPT-4o and Claude Opus models during a "Search and Read w/o Demo" task. Each chart visualizes the distribution of "Correct", "Wrong", and (for Claude Opus) "Invalid JSON" responses.
### Components/Axes
Each chart lacks explicit axes, as it's a pie chart representing proportions. The charts are labeled with the model name and task description at the top. Each slice of the pie chart is labeled with the category name and percentage, along with the absolute count in parentheses.
* **GPT-4o Chart:**
* Categories: "Correct", "Wrong"
* Colors: Light Green, Red
* **Claude Opus Chart:**
* Categories: "Correct", "Wrong", "Invalid JSON"
* Colors: Light Green, Red, Dark Blue
### Detailed Analysis or Content Details
**GPT-4o Chart:**
* **Correct:** 22.7% (27) - Represented by a light green slice.
* **Wrong:** 77.3% (92) - Represented by a red slice.
* The red slice dominates the chart, indicating a significantly higher proportion of incorrect responses.
**Claude Opus Chart:**
* **Correct:** 27.7% (33) - Represented by a light green slice.
* **Wrong:** 65.5% (78) - Represented by a red slice.
* **Invalid JSON:** 6.7% (8) - Represented by a dark blue slice.
* The red slice is the largest, but smaller than the GPT-4o's "Wrong" slice.
* The "Invalid JSON" slice is relatively small, but represents a distinct error type.
### Key Observations
* Both models exhibit a higher error rate ("Wrong" responses) than correct responses.
* GPT-4o has a higher percentage of "Wrong" responses (77.3%) compared to Claude Opus (65.5%).
* Claude Opus has an additional error category, "Invalid JSON", which accounts for 6.7% of its responses.
* The absolute counts (in parentheses) provide context to the percentages, showing the sample size for each model.
### Interpretation
The data suggests that both GPT-4o and Claude Opus struggle with the "Search and Read w/o Demo" task, producing more incorrect responses than correct ones. GPT-4o appears to be less accurate than Claude Opus in this specific scenario, as evidenced by its higher "Wrong" response rate. The presence of "Invalid JSON" errors in Claude Opus indicates a potential issue with its output formatting, possibly related to the search and read process.
The task description "Search and Read w/o Demo" implies that the models are being evaluated on their ability to extract information from a source and provide a response, without the benefit of a demonstration or example. This could be a challenging task, requiring strong natural language understanding and reasoning capabilities. The high error rates suggest that both models still have room for improvement in these areas.
The difference in error types (JSON validity for Claude Opus) could indicate differences in the models' architectures or training data. Further investigation would be needed to understand the root causes of these errors and develop strategies to mitigate them. The relatively small sample sizes (27 for GPT-4o correct, 33 for Claude Opus correct) should be considered when interpreting these results; larger sample sizes would provide more statistically significant conclusions.