## Pie Charts: Errors GPT-4o and Claude Opus (Search and Read w/o Demo)
### Overview
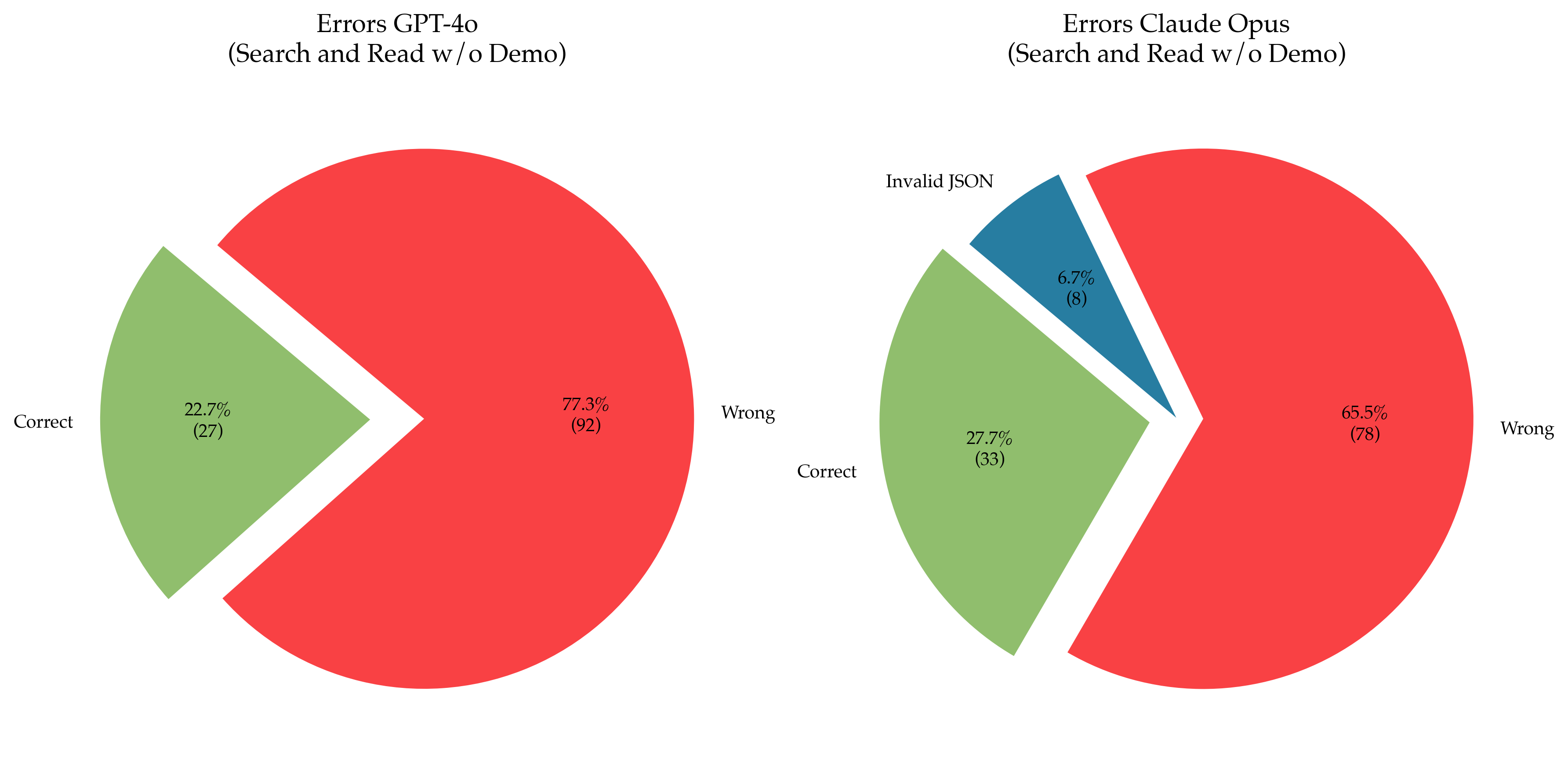
The image contains two side-by-side pie charts comparing error distributions for two AI models: GPT-4o and Claude Opus, during search and read tasks without demonstration. Each chart breaks down errors into categories with percentages and absolute counts.
### Components/Axes
- **X-Axis**: Not applicable (pie charts use radial segments).
- **Y-Axis**: Not applicable (pie charts use radial segments).
- **Legend**:
- **GPT-4o**:
- Green = Correct (22.7%, 27 instances)
- Red = Wrong (77.3%, 92 instances)
- **Claude Opus**:
- Green = Correct (27.7%, 33 instances)
- Red = Wrong (65.5%, 78 instances)
- Blue = Invalid JSON (6.7%, 8 instances)
- **Title**:
- Left chart: "Errors GPT-4o (Search and Read w/o Demo)"
- Right chart: "Errors Claude Opus (Search and Read w/o Demo)"
### Detailed Analysis
#### GPT-4o Errors
- **Correct**: 22.7% (27 instances) in green.
- **Wrong**: 77.3% (92 instances) in red, dominating the chart.
- **Trend**: Overwhelming majority of errors are "Wrong," indicating poor performance in search and read tasks without demonstration.
#### Claude Opus Errors
- **Correct**: 27.7% (33 instances) in green.
- **Wrong**: 65.5% (78 instances) in red.
- **Invalid JSON**: 6.7% (8 instances) in blue, a unique error category not present in GPT-4o.
- **Trend**: Lower "Wrong" errors compared to GPT-4o, but still a majority. Introduction of "Invalid JSON" errors suggests additional failure modes.
### Key Observations
1. **Error Distribution**:
- GPT-4o has a significantly higher proportion of "Wrong" errors (77.3%) compared to Claude Opus (65.5%).
- Claude Opus introduces a new error type ("Invalid JSON"), absent in GPT-4o.
2. **Accuracy**:
- Claude Opus shows marginally better correctness (27.7% vs. 22.7% for GPT-4o).
3. **Error Types**:
- GPT-4o errors are binary (Correct/Wrong), while Claude Opus includes a third category (Invalid JSON).
### Interpretation
The data suggests that Claude Opus performs slightly better in search and read tasks without demonstration, with a lower proportion of "Wrong" errors. However, its introduction of "Invalid JSON" errors indicates potential issues with input validation or parsing. GPT-4o’s higher "Wrong" error rate highlights limitations in task accuracy, possibly due to reliance on contextual understanding without demonstration. The presence of "Invalid JSON" in Claude Opus may reflect stricter input requirements or different architectural handling of malformed data. These differences underscore trade-offs in model design for specific task scenarios.