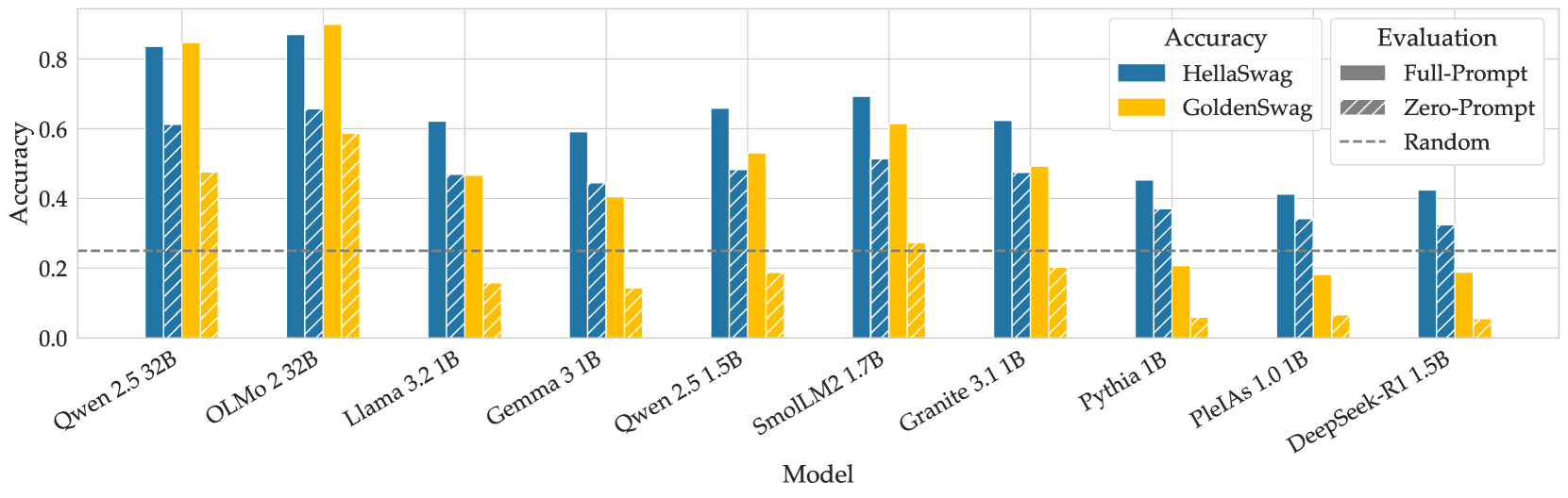
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: HellaSwag and GoldenSwag. The chart also shows the performance of these models under two evaluation conditions: Full-Prompt and Zero-Prompt. A horizontal dashed line indicates a "Random" baseline.
### Components/Axes
* **X-axis:** "Model" - Lists the names of the language models being compared: Qwen 2.5 32B, OLMo 2 32B, Llama 3.2 1B, Gemma 3 1B, Qwen 2.5 1.5B, SmolLM2 1.7B, Granite 3.1 1B, Pythia 1B, PlelAs 1.0 1B, DeepSeek-R1 1.5B.
* **Y-axis:** "Accuracy" - Ranges from 0.0 to 0.8 in increments of 0.2.
* **Legend (Top-Right):**
* **Accuracy:**
* Blue: HellaSwag
* Yellow: GoldenSwag
* **Evaluation:**
* Gray: Full-Prompt
* Diagonal Blue Stripes on Yellow: Zero-Prompt
* Dashed Gray Line: Random
### Detailed Analysis
The chart presents accuracy scores for each model under different conditions. The "Full-Prompt" evaluation is represented by solid bars, while "Zero-Prompt" is represented by bars with diagonal stripes.
Here's a breakdown of the approximate accuracy values for each model:
* **Qwen 2.5 32B:**
* HellaSwag (Full-Prompt): ~0.61
* GoldenSwag (Zero-Prompt): ~0.82
* **OLMo 2 32B:**
* HellaSwag (Full-Prompt): ~0.83
* GoldenSwag (Zero-Prompt): ~0.86
* **Llama 3.2 1B:**
* HellaSwag (Full-Prompt): ~0.65
* GoldenSwag (Zero-Prompt): ~0.47
* **Gemma 3 1B:**
* HellaSwag (Full-Prompt): ~0.53
* GoldenSwag (Zero-Prompt): ~0.15
* **Qwen 2.5 1.5B:**
* HellaSwag (Full-Prompt): ~0.64
* GoldenSwag (Zero-Prompt): ~0.20
* **SmolLM2 1.7B:**
* HellaSwag (Full-Prompt): ~0.61
* GoldenSwag (Zero-Prompt): ~0.48
* **Granite 3.1 1B:**
* HellaSwag (Full-Prompt): ~0.60
* GoldenSwag (Zero-Prompt): ~0.20
* **Pythia 1B:**
* HellaSwag (Full-Prompt): ~0.44
* GoldenSwag (Zero-Prompt): ~0.05
* **PlelAs 1.0 1B:**
* HellaSwag (Full-Prompt): ~0.30
* GoldenSwag (Zero-Prompt): ~0.07
* **DeepSeek-R1 1.5B:**
* HellaSwag (Full-Prompt): ~0.42
* GoldenSwag (Zero-Prompt): ~0.02
The "Random" baseline is at approximately 0.25.
### Key Observations
* OLMo 2 32B and Qwen 2.5 32B generally exhibit the highest accuracy on HellaSwag.
* GoldenSwag accuracy varies significantly across models, with some models performing close to the random baseline.
* The difference between Full-Prompt (HellaSwag) and Zero-Prompt (GoldenSwag) performance is substantial for most models, indicating a sensitivity to prompting strategy.
### Interpretation
The chart illustrates the performance of various language models on two different tasks, HellaSwag and GoldenSwag, under different prompting conditions. The results suggest that model architecture and size play a significant role in accuracy, as evidenced by the higher performance of OLMo 2 32B and Qwen 2.5 32B. The substantial difference between Full-Prompt and Zero-Prompt performance highlights the importance of prompt engineering in achieving optimal results with these models. The models' performance relative to the "Random" baseline indicates their ability to perform better than chance, but the degree of improvement varies widely. The GoldenSwag task appears to be more challenging, as many models struggle to significantly outperform the random baseline in the Zero-Prompt setting.