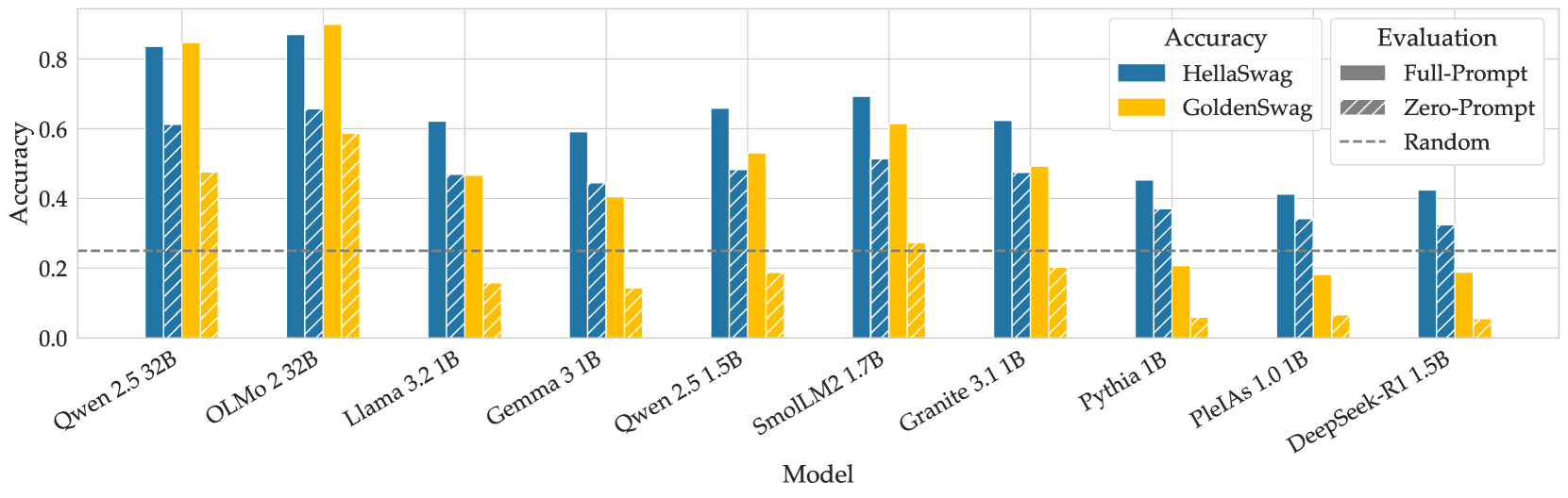
\n
## Bar Chart: Model Accuracy on HellaSwag and GoldenSwag
### Overview
This bar chart compares the accuracy of several language models on two evaluation datasets: HellaSwag and GoldenSwag, using both Full-Prompt and Zero-Prompt evaluation methods. A baseline "Random" accuracy is also shown. The chart displays accuracy scores on the Y-axis and model names on the X-axis.
### Components/Axes
* **X-axis:** Model - with the following categories: Qwen 1.5 32B, OLMo 2.32B, Llama 3.2 1B, Gemma 3 1B, Qwen 2.5 1.5B, SmollM2 1.7B, Granite 3.1 1B, Pythia 1B, PleiAs 1.0 1B, DeepSeek-R1 1.5B.
* **Y-axis:** Accuracy - ranging from 0.0 to 0.85, with increments of 0.2.
* **Legend:**
* **Accuracy:**
* HellaSwag (Blue)
* GoldenSwag (Yellow)
* **Evaluation:**
* Full-Prompt (Solid Line)
* Zero-Prompt (Hatched Line)
* Random (Dashed Line)
### Detailed Analysis
The chart consists of paired bars for each model, representing HellaSwag and GoldenSwag accuracy. Each pair has two bars: one for HellaSwag (blue) and one for GoldenSwag (yellow). Superimposed on these bars are lines representing the Full-Prompt and Zero-Prompt evaluation methods. The Random accuracy is shown as a horizontal dashed line.
Here's a breakdown of the approximate accuracy values for each model:
* **Qwen 1.5 32B:**
* HellaSwag (Full-Prompt): ~0.82
* HellaSwag (Zero-Prompt): ~0.78
* GoldenSwag (Full-Prompt): ~0.64
* GoldenSwag (Zero-Prompt): ~0.60
* **OLMo 2.32B:**
* HellaSwag (Full-Prompt): ~0.74
* HellaSwag (Zero-Prompt): ~0.68
* GoldenSwag (Full-Prompt): ~0.62
* GoldenSwag (Zero-Prompt): ~0.56
* **Llama 3.2 1B:**
* HellaSwag (Full-Prompt): ~0.64
* HellaSwag (Zero-Prompt): ~0.58
* GoldenSwag (Full-Prompt): ~0.52
* GoldenSwag (Zero-Prompt): ~0.46
* **Gemma 3 1B:**
* HellaSwag (Full-Prompt): ~0.60
* HellaSwag (Zero-Prompt): ~0.54
* GoldenSwag (Full-Prompt): ~0.50
* GoldenSwag (Zero-Prompt): ~0.44
* **Qwen 2.5 1.5B:**
* HellaSwag (Full-Prompt): ~0.62
* HellaSwag (Zero-Prompt): ~0.56
* GoldenSwag (Full-Prompt): ~0.54
* GoldenSwag (Zero-Prompt): ~0.48
* **SmollM2 1.7B:**
* HellaSwag (Full-Prompt): ~0.54
* HellaSwag (Zero-Prompt): ~0.48
* GoldenSwag (Full-Prompt): ~0.46
* GoldenSwag (Zero-Prompt): ~0.40
* **Granite 3.1 1B:**
* HellaSwag (Full-Prompt): ~0.64
* HellaSwag (Zero-Prompt): ~0.58
* GoldenSwag (Full-Prompt): ~0.56
* GoldenSwag (Zero-Prompt): ~0.50
* **Pythia 1B:**
* HellaSwag (Full-Prompt): ~0.60
* HellaSwag (Zero-Prompt): ~0.54
* GoldenSwag (Full-Prompt): ~0.52
* GoldenSwag (Zero-Prompt): ~0.46
* **PleiAs 1.0 1B:**
* HellaSwag (Full-Prompt): ~0.56
* HellaSwag (Zero-Prompt): ~0.50
* GoldenSwag (Full-Prompt): ~0.48
* GoldenSwag (Zero-Prompt): ~0.42
* **DeepSeek-R1 1.5B:**
* HellaSwag (Full-Prompt): ~0.48
* HellaSwag (Zero-Prompt): ~0.42
* GoldenSwag (Full-Prompt): ~0.38
* GoldenSwag (Zero-Prompt): ~0.32
The Random accuracy line is approximately at 0.2.
### Key Observations
* Qwen 1.5 32B consistently demonstrates the highest accuracy on both HellaSwag and GoldenSwag datasets, across both evaluation methods.
* HellaSwag accuracy is generally higher than GoldenSwag accuracy for all models.
* Full-Prompt evaluation consistently yields higher accuracy scores than Zero-Prompt evaluation for each model.
* The performance gap between Full-Prompt and Zero-Prompt is more pronounced for higher-performing models like Qwen 1.5 32B.
* DeepSeek-R1 1.5B exhibits the lowest accuracy scores among the models tested.
### Interpretation
The chart demonstrates the varying capabilities of different language models in commonsense reasoning, as assessed by the HellaSwag and GoldenSwag datasets. The higher accuracy of Qwen 1.5 32B suggests a stronger ability to understand and predict plausible continuations of given scenarios. The difference in accuracy between the two datasets indicates that HellaSwag might be an easier task than GoldenSwag. The consistent improvement from Zero-Prompt to Full-Prompt evaluation highlights the importance of providing contextual information (the "prompt") to these models for optimal performance. The Random accuracy line serves as a baseline, indicating that the models are performing significantly better than chance. The models with lower accuracy, like DeepSeek-R1 1.5B, may benefit from further training or architectural improvements. The size of the model (indicated by the "B" parameter, representing billions of parameters) appears to correlate with performance, but is not the sole determining factor, as evidenced by the performance of models with similar parameter counts.