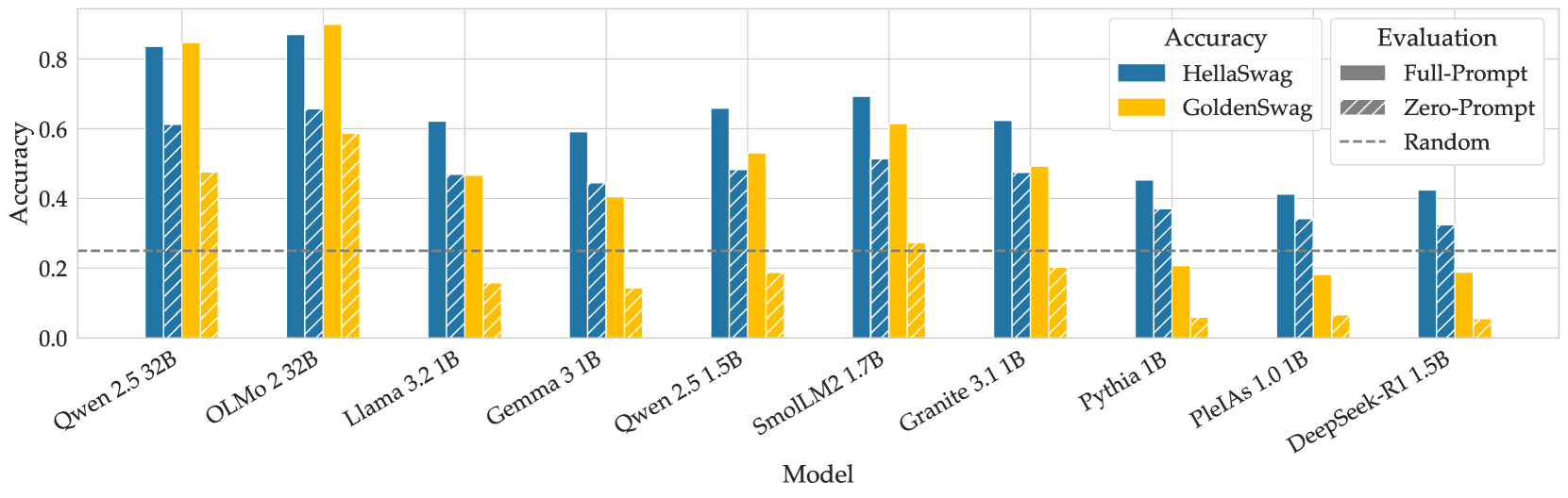
\n
## Grouped Bar Chart: Model Accuracy Comparison on HellaSwag and GoldenSwag
### Overview
This image is a grouped bar chart comparing the accuracy of ten different language models on two evaluation datasets: HellaSwag and GoldenSwag. The chart evaluates each model under two prompting conditions (Full-Prompt and Zero-Prompt) and includes a random baseline for reference.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **X-Axis (Horizontal):** Labeled "Model". It lists ten specific language models. From left to right:
1. Qwen 2.5 32B
2. OLMo 2 32B
3. Llama 3.2 1B
4. Gemma 3 1B
5. Qwen 2.5 1.5B
6. SmolLM2 1.7B
7. Granite 3.1 1B
8. Pythia 1B
9. PleIAs 1.0 1B
10. DeepSeek-R1 5B
* **Y-Axis (Vertical):** Labeled "Accuracy". The scale runs from 0.0 to 0.8, with major gridlines at intervals of 0.2.
* **Legend (Top-Right Corner):**
* **Accuracy (Color Key):**
* Blue solid bar: HellaSwag dataset.
* Yellow solid bar: GoldenSwag dataset.
* **Evaluation (Pattern Key):**
* Solid fill: Full-Prompt evaluation.
* Diagonal hatching (///): Zero-Prompt evaluation.
* **Baseline:** A dashed horizontal line labeled "Random" is positioned at approximately y=0.25.
### Detailed Analysis
The chart presents accuracy scores for each model across four conditions: HellaSwag Full-Prompt, HellaSwag Zero-Prompt, GoldenSwag Full-Prompt, and GoldenSwag Zero-Prompt. Values are approximate based on visual bar height.
**Trend Verification:**
* **HellaSwag (Blue Bars):** The general trend shows a decrease in accuracy from the larger models on the left (Qwen 2.5 32B, OLMo 2 32B) towards the smaller models on the right, with some fluctuation.
* **GoldenSwag (Yellow Bars):** This trend is less linear. The highest scores are on the left, but there is a notable dip for Llama 3.2 1B and Gemma 3 1B, followed by a partial recovery for SmolLM2 1.7B before declining again.
**Model-by-Model Data Points (Approximate):**
1. **Qwen 2.5 32B:**
* HellaSwag Full-Prompt: ~0.83
* HellaSwag Zero-Prompt: ~0.61
* GoldenSwag Full-Prompt: ~0.85
* GoldenSwag Zero-Prompt: ~0.48
2. **OLMo 2 32B:**
* HellaSwag Full-Prompt: ~0.87 (Highest HellaSwag score)
* HellaSwag Zero-Prompt: ~0.66
* GoldenSwag Full-Prompt: ~0.90 (Highest overall score)
* GoldenSwag Zero-Prompt: ~0.59
3. **Llama 3.2 1B:**
* HellaSwag Full-Prompt: ~0.62
* HellaSwag Zero-Prompt: ~0.47
* GoldenSwag Full-Prompt: ~0.47
* GoldenSwag Zero-Prompt: ~0.16
4. **Gemma 3 1B:**
* HellaSwag Full-Prompt: ~0.59
* HellaSwag Zero-Prompt: ~0.44
* GoldenSwag Full-Prompt: ~0.40
* GoldenSwag Zero-Prompt: ~0.14
5. **Qwen 2.5 1.5B:**
* HellaSwag Full-Prompt: ~0.66
* HellaSwag Zero-Prompt: ~0.49
* GoldenSwag Full-Prompt: ~0.53
* GoldenSwag Zero-Prompt: ~0.19
6. **SmolLM2 1.7B:**
* HellaSwag Full-Prompt: ~0.70
* HellaSwag Zero-Prompt: ~0.52
* GoldenSwag Full-Prompt: ~0.61
* GoldenSwag Zero-Prompt: ~0.28
7. **Granite 3.1 1B:**
* HellaSwag Full-Prompt: ~0.62
* HellaSwag Zero-Prompt: ~0.48
* GoldenSwag Full-Prompt: ~0.49
* GoldenSwag Zero-Prompt: ~0.20
8. **Pythia 1B:**
* HellaSwag Full-Prompt: ~0.45
* HellaSwag Zero-Prompt: ~0.37
* GoldenSwag Full-Prompt: ~0.20
* GoldenSwag Zero-Prompt: ~0.06
9. **PleIAs 1.0 1B:**
* HellaSwag Full-Prompt: ~0.41
* HellaSwag Zero-Prompt: ~0.34
* GoldenSwag Full-Prompt: ~0.18
* GoldenSwag Zero-Prompt: ~0.06
10. **DeepSeek-R1 5B:**
* HellaSwag Full-Prompt: ~0.42
* HellaSwag Zero-Prompt: ~0.32
* GoldenSwag Full-Prompt: ~0.19
* GoldenSwag Zero-Prompt: ~0.05
### Key Observations
1. **Top Performers:** The two 32B parameter models (Qwen 2.5 32B and OLMo 2 32B) significantly outperform all smaller models on both datasets, especially under the Full-Prompt condition.
2. **Prompting Impact:** For every model and every dataset, the Full-Prompt evaluation (solid bar) yields higher accuracy than the Zero-Prompt evaluation (hatched bar). The performance gap is often substantial, particularly for the GoldenSwag dataset.
3. **Dataset Difficulty:** For most models, accuracy on GoldenSwag (yellow) is lower than on HellaSwag (blue) under the same prompting condition. This suggests GoldenSwag is a more challenging benchmark for these models.
4. **Random Baseline:** All models perform above the random baseline (dashed line at ~0.25) in the Full-Prompt setting. However, several models' Zero-Prompt scores on GoldenSwag (e.g., Pythia, PleIAs, DeepSeek-R1) fall below this random threshold.
5. **Model Size vs. Performance:** While the largest models lead, the relationship isn't perfectly linear among the smaller models. For instance, SmolLM2 1.7B outperforms several other 1B-class models.
### Interpretation
This chart provides a comparative snapshot of model capabilities on commonsense reasoning tasks (HellaSwag) and a related, possibly more difficult, benchmark (GoldenSwag). The data suggests several key insights:
* **Scale is a Dominant Factor:** The dramatic performance leap of the 32B models underscores the continued importance of model scale for achieving high accuracy on these benchmarks.
* **Prompting is Critical:** The consistent and large advantage of Full-Prompt over Zero-Prompt evaluations highlights that these models are highly sensitive to the format and context provided in the input. Their "raw," unprompted reasoning ability is significantly weaker.
* **Benchmark Sensitivity:** The generally lower scores on GoldenSwag indicate it may test a different or more nuanced aspect of reasoning than HellaSwag, or that the models' training data was less aligned with its content. The severe drop for some models (e.g., Llama 3.2 1B) on GoldenSwag Zero-Prompt is a notable anomaly, suggesting a particular weakness in that specific evaluation setting.
* **Practical Implications:** For practitioners, this data argues for using larger models when possible and, crucially, for investing effort in prompt engineering (Full-Prompt) to unlock a model's performance potential. It also cautions that performance on one benchmark (HellaSwag) does not perfectly predict performance on another (GoldenSwag).