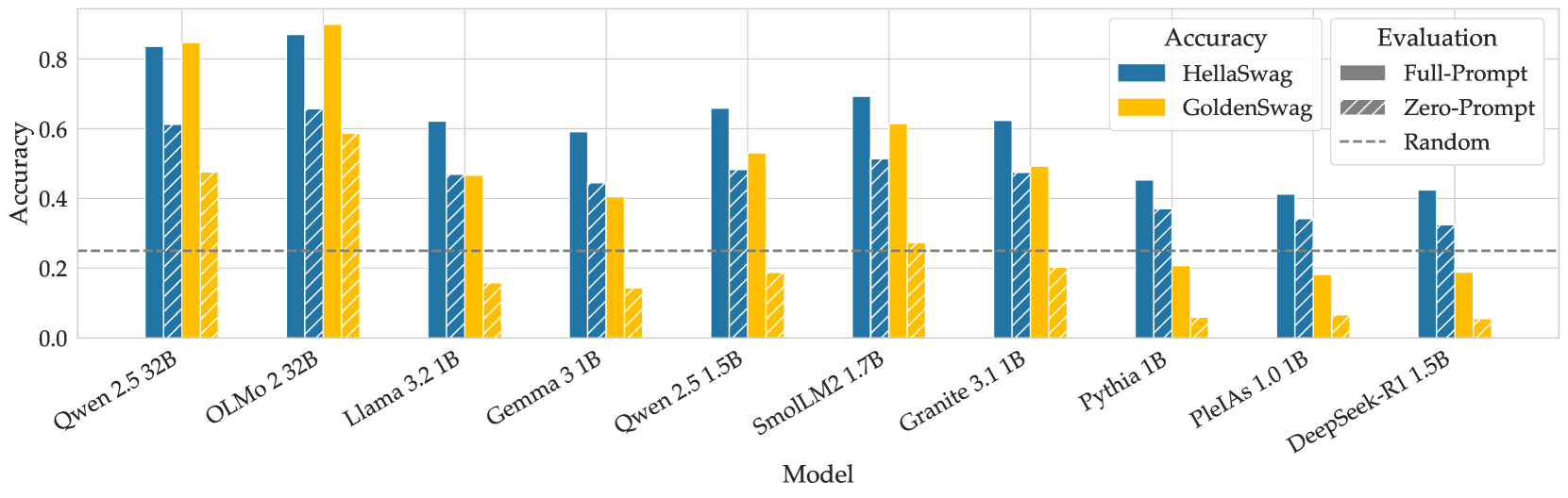
## Bar Chart: Model Accuracy Comparison
### Overview
The chart compares the accuracy of various language models (LMs) on two evaluation methods: **HellaSwag** (blue bars) and **GoldenSwag** (orange bars). A dashed horizontal line at ~0.25 represents the "Random" baseline. Models are listed on the x-axis, with accuracy values on the y-axis (0–0.8).
### Components/Axes
- **X-axis (Model)**:
- Qwen 2.5 32B
- OLMo 2.32B
- Llama 3.2 1B
- Gemma 3.1B
- Qwen 2.5 1.5B
- SmolLM2 1.7B
- Granite 3.1B
- Pythia 1B
- PleiAs 1.0 1B
- DeepSeek-R1 1.5B
- **Y-axis (Accuracy)**: 0.0 to 0.8 in increments of 0.2.
- **Legend**:
- **Blue (HellaSwag)**: Full-Prompt evaluation.
- **Orange (GoldenSwag)**: Zero-Prompt evaluation.
- **Dashed Line (Random)**: Baseline accuracy (~0.25).
### Detailed Analysis
- **HellaSwag (Blue)**:
- Highest accuracy: **OLMo 2.32B (0.85)**.
- Lowest accuracy: **DeepSeek-R1 1.5B (0.42)**.
- Most models exceed the random baseline (0.25), with values ranging from 0.42 to 0.85.
- **GoldenSwag (Orange)**:
- Highest accuracy: **OLMo 2.32B (0.6)**.
- Lowest accuracy: **PleiAs 1.0 1B (0.18)**.
- Many models fall below the random baseline (e.g., PleiAs 1.0 1B, DeepSeek-R1 1.5B).
- **Random Baseline**:
- All models’ HellaSwag accuracies exceed this line.
- Only **OLMo 2.32B (GoldenSwag)** and **Qwen 2.5 1.5B (GoldenSwag)** approach the baseline (~0.5).
### Key Observations
1. **HellaSwag Dominance**: HellaSwag consistently outperforms GoldenSwag across all models.
2. **Model Size Correlation**: Larger models (e.g., Qwen 2.5 32B, OLMo 2.32B) generally achieve higher accuracy.
3. **GoldenSwag Limitations**: Many models (e.g., Pythia 1B, PleiAs 1.0 1B) perform near or below random chance with GoldenSwag.
4. **Outliers**:
- **SmolLM2 1.7B**: GoldenSwag accuracy (0.3) is significantly lower than HellaSwag (0.7).
- **DeepSeek-R1 1.5B**: Both methods underperform, with HellaSwag at 0.42.
### Interpretation
The data suggests that **HellaSwag** is a more robust evaluation method for these models, as it consistently yields higher accuracy. GoldenSwag’s performance varies widely, with smaller models (e.g., Pythia 1B) struggling to surpass random chance. The random baseline highlights that some models’ zero-prompt evaluations (GoldenSwag) are ineffective, indicating potential flaws in the evaluation design or model capabilities. Larger models like OLMo 2.32B and Qwen 2.5 32B demonstrate strong performance, suggesting scalability benefits. However, the disparity between HellaSwag and GoldenSwag raises questions about the latter’s suitability for evaluating smaller or less capable models.