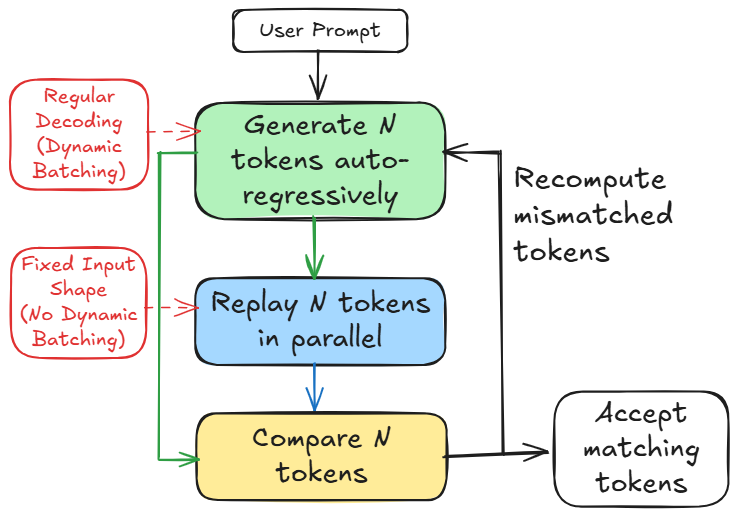
## Diagram: Token Generation and Verification Flowchart
### Overview
The image is a flowchart diagram illustrating a process for generating and verifying tokens, likely in the context of a language model or similar autoregressive system. The diagram uses color-coded boxes and directional arrows to depict a multi-step process with a feedback loop for error correction. It contrasts two operational modes indicated by side annotations.
### Components/Axes
The diagram consists of seven distinct text-containing elements connected by arrows:
1. **Top Center (White Box):** "User Prompt"
2. **Center Top (Green Box):** "Generate N tokens auto-regressively"
3. **Center Middle (Blue Box):** "Replay N tokens in parallel"
4. **Center Bottom (Yellow Box):** "Compare N tokens"
5. **Bottom Right (White Box):** "Accept matching tokens"
6. **Left Side, Top (Red Box):** "Regular Decoding (Dynamic Batching)"
7. **Left Side, Bottom (Red Box):** "Fixed Input Shape (No Dynamic Batching)"
8. **Right Side (Text, no box):** "Recompute mismatched tokens"
**Flow and Connections (Spatial Grounding):**
* The primary flow is vertical and downward: `User Prompt` → `Generate N tokens...` → `Replay N tokens...` → `Compare N tokens`.
* From `Compare N tokens`, a green arrow points right to `Accept matching tokens`.
* From `Compare N tokens`, a black arrow points up and right to the text `Recompute mismatched tokens`.
* From `Recompute mismatched tokens`, a black arrow points back to the left side of the `Generate N tokens...` box, creating a feedback loop.
* The two red boxes on the left have dashed red arrows pointing to the main process boxes:
* `Regular Decoding (Dynamic Batching)` points to the `Generate N tokens...` box.
* `Fixed Input Shape (No Dynamic Batching)` points to the `Replay N tokens...` box.
### Detailed Analysis
The process describes a two-stage token generation and verification system:
1. **Initialization:** The process begins with a "User Prompt".
2. **Stage 1 - Autoregressive Generation:** The system generates a sequence of `N` tokens one after another (auto-regressively). This stage is influenced by the "Regular Decoding (Dynamic Batching)" method.
3. **Stage 2 - Parallel Replay:** The same `N` tokens are then processed again, but this time in parallel. This stage operates under a "Fixed Input Shape (No Dynamic Batching)" constraint.
4. **Verification:** The outputs from the two stages (autoregressive generation and parallel replay) are compared.
5. **Decision Point:**
* If the tokens from both stages match, they are accepted (`Accept matching tokens`).
* If there is a mismatch, the system triggers a recomputation step (`Recompute mismatched tokens`) and loops back to the autoregressive generation stage to try again.
### Key Observations
* **Dual-Path Verification:** The core of the diagram is a verification mechanism that runs the same task (generating `N` tokens) through two different computational pathways (sequential auto-regressive vs. parallel replay) and compares the results.
* **Error Correction Loop:** The system has an explicit, iterative error-handling mechanism. A mismatch doesn't cause failure; it triggers a recomputation cycle.
* **Methodological Contrast:** The red annotations highlight a key technical contrast: "Dynamic Batching" (flexible, likely for the sequential step) versus "No Dynamic Batching" with a "Fixed Input Shape" (rigid, likely for the parallel step). This suggests the diagram may be explaining a technique to ensure consistency or catch errors between different execution modes of a model.
### Interpretation
This flowchart depicts a **speculative decoding** or **verification-based decoding** technique used to accelerate or stabilize text generation in large language models.
* **What it demonstrates:** The process aims to generate tokens quickly using a parallel method (the "Replay" step) but uses the traditional, slower auto-regressive method as a "ground truth" verifier. If the fast parallel guess matches the slow sequential answer, it's accepted, saving time. If not, the system falls back to recomputing with the reliable sequential method.
* **Relationship between elements:** The "User Prompt" is the input. The two generation methods (green and blue boxes) are competing or complementary pathways for producing the same output (`N` tokens). The "Compare" step is the arbiter. The red boxes define the operational constraints for each pathway, which is crucial for understanding why their outputs might differ.
* **Notable implication:** The primary goal is likely **efficiency**. By accepting the results of the faster parallel path when they are correct, the system can avoid the full computational cost of auto-regressive generation for every token. The feedback loop ensures **accuracy** is not sacrificed, as mismatches are caught and corrected. This represents a trade-off between speed and reliability, managed by an automated verification step.