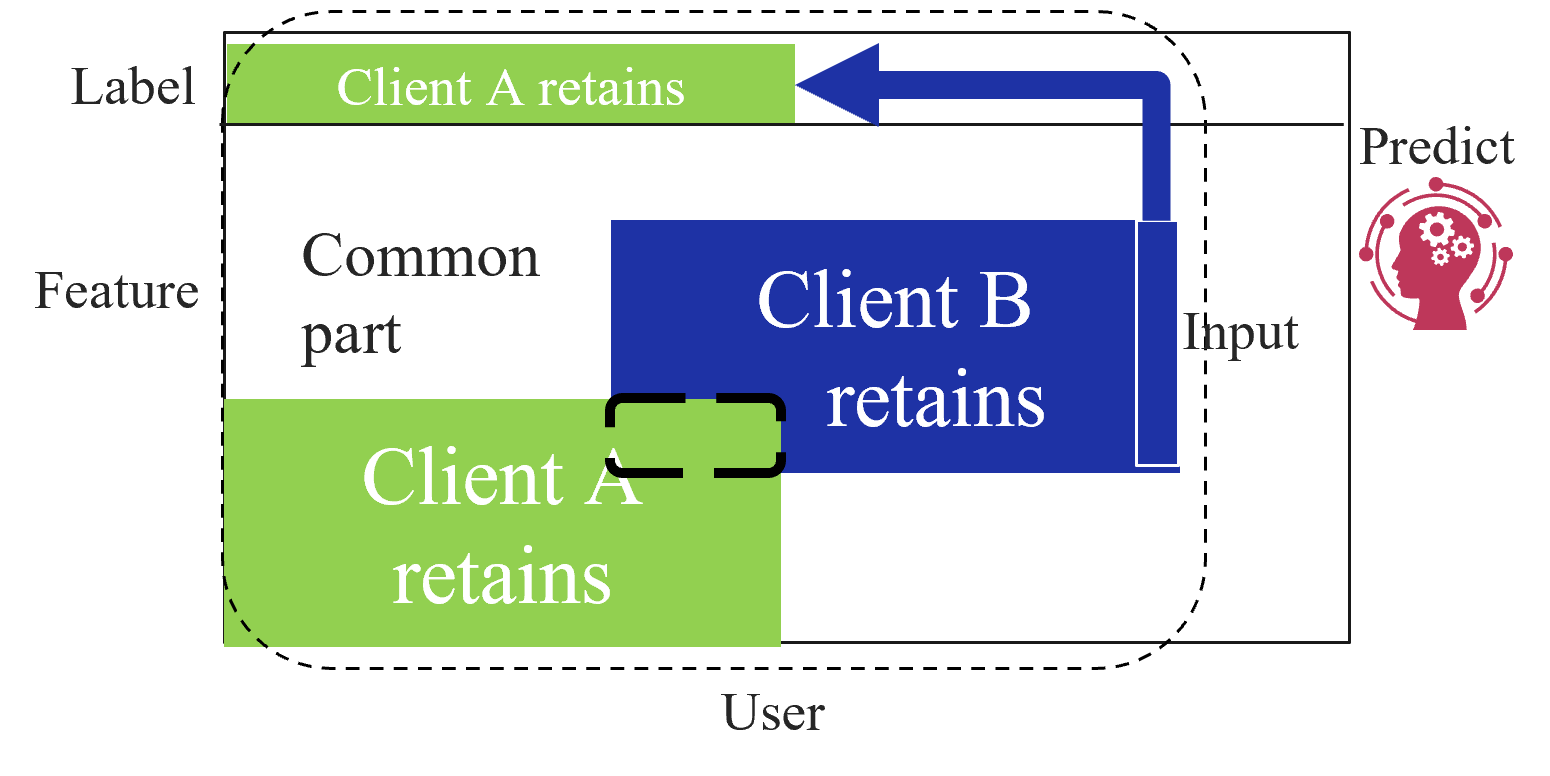
## Diagram: Client Data Retention and Prediction Flow
### Overview
The image is a conceptual block diagram illustrating a multi-tenant data architecture. It delineates how two entities, "Client A" and "Client B," retain data or features, and how these components interact with a prediction mechanism. The diagram uses color-coded blocks (green for Client A, blue for Client B) and directional arrows to represent data flow and ownership.
### Components/Axes
* **Main Container:** A large rectangle with a dashed border enclosing the primary logic.
* **Labels (External):**
* **Label:** Positioned to the left of the top row.
* **Feature:** Positioned to the left of the middle/bottom section.
* **Input:** Positioned to the right of the middle section.
* **User:** Positioned at the bottom center, outside the main container.
* **Predict:** Positioned to the right, accompanied by a circular icon featuring a silhouette of a head with gears inside.
* **Internal Blocks:**
* **Client A retains (Top):** A light green rectangle located in the top-left quadrant.
* **Client A retains (Bottom):** A light green rectangle located in the bottom-left quadrant.
* **Client B retains:** A large, dark blue rectangle located on the right side of the container.
* **Common part:** A white, empty space located in the center-left, between the two "Client A" blocks.
* **Dashed Box:** A small, empty rectangle with a dashed border located in the center, overlapping the boundary between the "Common part" and the "Client B retains" block.
* **Flow Indicator:** A thick, dark blue arrow originating from the "Client B retains" block, pointing left, and then turning upward to point toward the top "Client A retains" block.
### Detailed Analysis
* **Spatial Grounding:**
* The diagram is organized into a grid-like structure.
* The top row is associated with the "Label" category.
* The middle/bottom rows are associated with the "Feature" category.
* The right side is associated with "Input."
* **Data Series/Ownership:**
* **Client A:** Occupies two distinct green zones. The top zone is aligned with the "Label" category, while the bottom zone is aligned with the "Feature" category.
* **Client B:** Occupies a single, large blue zone on the right, which appears to encompass both the "Label" and "Feature" vertical space.
* **Common Part:** A neutral white space exists between the Client A and Client B zones, suggesting shared or non-proprietary data.
* **Flow Logic:**
* The blue arrow indicates a directional dependency or data transfer. It suggests that information or a processed result from "Client B retains" is fed back into the top "Client A retains" section.
### Key Observations
* **Asymmetry:** Client B has a single, large, contiguous block, whereas Client A has two separated blocks.
* **The "Predict" Icon:** The "Predict" label and associated icon are placed outside the main container, suggesting that the prediction service is an external process or an overarching system that interacts with the internal data blocks.
* **The Dashed Box:** The small dashed box in the center is a focal point, likely representing a specific intersection, a "hot" zone, or a point of conflict/integration between the "Common part" and "Client B."
### Interpretation
This diagram likely represents a machine learning or data processing pipeline in a multi-tenant environment:
1. **Multi-Tenancy:** The system separates data retention by client ("Client A" vs. "Client B").
2. **Feature/Label Separation:** The vertical alignment suggests that "Label" data and "Feature" data are handled differently or stored in different segments.
3. **Prediction Pipeline:** The "Predict" icon suggests that the system takes "Input" (likely from Client B) and performs a prediction.
4. **Feedback Loop:** The blue arrow is the most critical element; it implies that the output of the prediction (or the data retained by Client B) is utilized to update or inform the "Label" data for Client A. This could represent a transfer learning scenario, where a model trained on Client B's data is used to generate labels or features for Client A.
5. **Commonality:** The "Common part" suggests that there is a shared infrastructure or dataset that both clients utilize, which is distinct from their private, retained data.