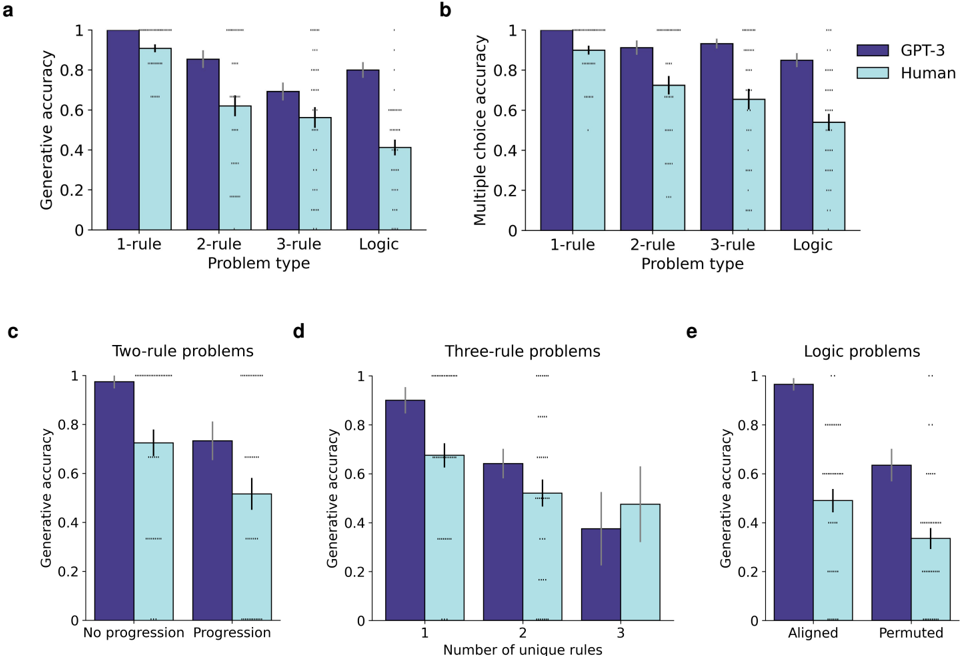
\n
## Bar Charts: Accuracy of GPT-3 and Humans on Rule-Based Problems
### Overview
The image presents five bar charts (labeled a, b, c, d, and e) comparing the accuracy of GPT-3 and humans on various rule-based problem types. Charts a and b compare generative and multiple-choice accuracy respectively, across different numbers of rules (1-rule, 2-rule, 3-rule, and Logic). Charts c, d, and e provide more granular breakdowns for specific problem types: two-rule problems with/without progression, three-rule problems with varying numbers of unique rules, and logic problems with aligned/permuted rules. Error bars are present on all bars, indicating the variability in the data.
### Components/Axes
* **Y-axis (a, c, d, e):** Generative Accuracy (scale from 0 to 1)
* **Y-axis (b):** Multiple Choice Accuracy (scale from 0 to 1)
* **X-axis (a, b):** Problem Type (1-rule, 2-rule, 3-rule, Logic)
* **X-axis (c):** No progression, Progression
* **X-axis (d):** Number of unique rules (1, 2, 3)
* **X-axis (e):** Aligned, Permuted
* **Legend:**
* Dark Purple: GPT-3
* Light Blue: Human
### Detailed Analysis or Content Details
**Chart a: Generative Accuracy vs. Problem Type**
* **1-rule:** GPT-3 accuracy is approximately 0.92 ± 0.03. Human accuracy is approximately 0.85 ± 0.05.
* **2-rule:** GPT-3 accuracy is approximately 0.85 ± 0.04. Human accuracy is approximately 0.75 ± 0.06.
* **3-rule:** GPT-3 accuracy is approximately 0.72 ± 0.06. Human accuracy is approximately 0.65 ± 0.07.
* **Logic:** GPT-3 accuracy is approximately 0.52 ± 0.08. Human accuracy is approximately 0.48 ± 0.09.
**Chart b: Multiple Choice Accuracy vs. Problem Type**
* **1-rule:** GPT-3 accuracy is approximately 0.85 ± 0.04. Human accuracy is approximately 0.82 ± 0.05.
* **2-rule:** GPT-3 accuracy is approximately 0.82 ± 0.05. Human accuracy is approximately 0.78 ± 0.06.
* **3-rule:** GPT-3 accuracy is approximately 0.75 ± 0.06. Human accuracy is approximately 0.70 ± 0.07.
* **Logic:** GPT-3 accuracy is approximately 0.62 ± 0.07. Human accuracy is approximately 0.58 ± 0.08.
**Chart c: Generative Accuracy - Two-Rule Problems**
* **No progression:** GPT-3 accuracy is approximately 0.78 ± 0.05. Human accuracy is approximately 0.82 ± 0.04.
* **Progression:** GPT-3 accuracy is approximately 0.62 ± 0.07. Human accuracy is approximately 0.68 ± 0.06.
**Chart d: Generative Accuracy - Three-Rule Problems**
* **1 unique rule:** GPT-3 accuracy is approximately 0.85 ± 0.03. Human accuracy is approximately 0.75 ± 0.05.
* **2 unique rules:** GPT-3 accuracy is approximately 0.62 ± 0.06. Human accuracy is approximately 0.55 ± 0.07.
* **3 unique rules:** GPT-3 accuracy is approximately 0.48 ± 0.08. Human accuracy is approximately 0.52 ± 0.08.
**Chart e: Generative Accuracy - Logic Problems**
* **Aligned:** GPT-3 accuracy is approximately 0.65 ± 0.06. Human accuracy is approximately 0.55 ± 0.07.
* **Permuted:** GPT-3 accuracy is approximately 0.42 ± 0.08. Human accuracy is approximately 0.40 ± 0.09.
### Key Observations
* GPT-3 generally outperforms humans on 1-rule and 2-rule problems in both generative and multiple-choice formats.
* As the number of rules increases, the performance gap between GPT-3 and humans narrows, and humans sometimes outperform GPT-3 (e.g., two-rule problems with no progression).
* GPT-3's performance drops significantly on logic problems, especially when the rules are permuted.
* The error bars indicate substantial variability in the data, suggesting that individual performance can vary considerably.
### Interpretation
The data suggests that GPT-3 excels at tasks requiring the application of a small number of simple rules. However, its performance degrades as the complexity of the rules increases, particularly when dealing with logical reasoning. This could be due to GPT-3's reliance on pattern recognition rather than true understanding of the underlying logic. The human performance, while generally lower than GPT-3's on simpler tasks, is more robust to increases in complexity, suggesting a greater capacity for abstract reasoning. The difference in performance between aligned and permuted logic problems for both GPT-3 and humans indicates that the order of rules can impact performance, potentially due to cognitive load or the difficulty of identifying patterns when the rules are presented in a non-intuitive order. The error bars highlight the importance of considering individual variability when evaluating the performance of both GPT-3 and humans on these tasks. The charts demonstrate a trade-off between the ability of GPT-3 to quickly learn simple rules and the human ability to generalize and reason with more complex rule sets.