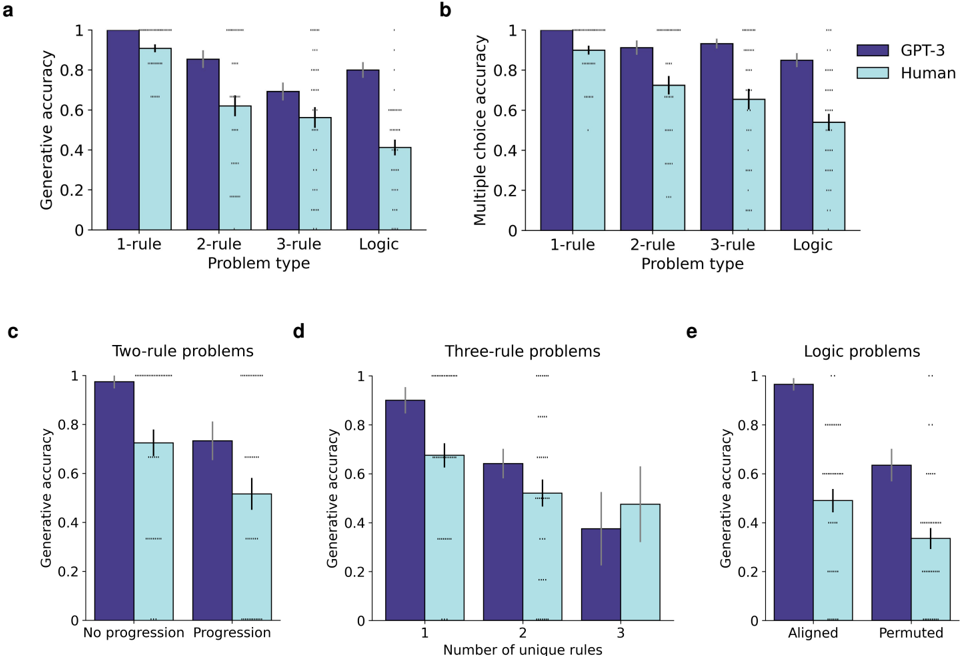
\n
## Bar Charts: GPT-3 vs. Human Performance on Reasoning Problems
### Overview
The image contains five bar charts (labeled a, b, c, d, e) comparing the performance of GPT-3 (dark purple bars) and Human participants (light blue bars) on various types of reasoning problems. The charts measure accuracy (generative or multiple-choice) across different problem categories and conditions. All text is in English.
### Components/Axes
* **Legend:** Located in the top-right corner of subplot **b**. It defines the two data series:
* **GPT-3:** Dark purple bars.
* **Human:** Light blue bars.
* **Subplot a:**
* **Title/Label:** "a" (top-left corner).
* **Y-axis:** "Generative accuracy" (scale 0 to 1).
* **X-axis:** "Problem type" with categories: "1-rule", "2-rule", "3-rule", "Logic".
* **Subplot b:**
* **Title/Label:** "b" (top-left corner).
* **Y-axis:** "Multiple choice accuracy" (scale 0 to 1).
* **X-axis:** "Problem type" with categories: "1-rule", "2-rule", "3-rule", "Logic".
* **Subplot c:**
* **Title/Label:** "c" (top-left corner). **Chart Title:** "Two-rule problems".
* **Y-axis:** "Generative accuracy" (scale 0 to 1).
* **X-axis:** Categories: "No progression", "Progression".
* **Subplot d:**
* **Title/Label:** "d" (top-left corner). **Chart Title:** "Three-rule problems".
* **Y-axis:** "Generative accuracy" (scale 0 to 1).
* **X-axis:** "Number of unique rules" with categories: "1", "2", "3".
* **Subplot e:**
* **Title/Label:** "e" (top-left corner). **Chart Title:** "Logic problems".
* **Y-axis:** "Generative accuracy" (scale 0 to 1).
* **X-axis:** Categories: "Aligned", "Permuted".
### Detailed Analysis
**Subplot a (Generative Accuracy by Problem Type):**
* **Trend:** Accuracy for both GPT-3 and Humans decreases as problem complexity increases (from 1-rule to Logic). GPT-3 consistently outperforms Humans.
* **Data Points (Approximate):**
* **1-rule:** GPT-3 ≈ 1.0, Human ≈ 0.9.
* **2-rule:** GPT-3 ≈ 0.85, Human ≈ 0.62.
* **3-rule:** GPT-3 ≈ 0.70, Human ≈ 0.58.
* **Logic:** GPT-3 ≈ 0.80, Human ≈ 0.42.
**Subplot b (Multiple Choice Accuracy by Problem Type):**
* **Trend:** Similar decreasing trend with complexity. GPT-3 maintains a significant lead over Humans.
* **Data Points (Approximate):**
* **1-rule:** GPT-3 ≈ 1.0, Human ≈ 0.90.
* **2-rule:** GPT-3 ≈ 0.92, Human ≈ 0.72.
* **3-rule:** GPT-3 ≈ 0.94, Human ≈ 0.65.
* **Logic:** GPT-3 ≈ 0.85, Human ≈ 0.55.
**Subplot c (Two-rule Problems - Generative Accuracy):**
* **Trend:** For both groups, accuracy is lower on "Progression" problems compared to "No progression" problems.
* **Data Points (Approximate):**
* **No progression:** GPT-3 ≈ 0.98, Human ≈ 0.72.
* **Progression:** GPT-3 ≈ 0.74, Human ≈ 0.52.
**Subplot d (Three-rule Problems - Generative Accuracy):**
* **Trend:** Accuracy for both groups decreases as the "Number of unique rules" increases from 1 to 3.
* **Data Points (Approximate):**
* **1 unique rule:** GPT-3 ≈ 0.90, Human ≈ 0.68.
* **2 unique rules:** GPT-3 ≈ 0.65, Human ≈ 0.52.
* **3 unique rules:** GPT-3 ≈ 0.38, Human ≈ 0.48.
**Subplot e (Logic Problems - Generative Accuracy):**
* **Trend:** Both groups perform significantly better on "Aligned" problems than on "Permuted" problems.
* **Data Points (Approximate):**
* **Aligned:** GPT-3 ≈ 0.98, Human ≈ 0.50.
* **Permuted:** GPT-3 ≈ 0.64, Human ≈ 0.34.
### Key Observations
1. **Consistent Superiority:** GPT-3's accuracy is higher than Human accuracy across all problem types and conditions shown.
2. **Complexity Impact:** Performance for both entities degrades as the logical complexity of the problem increases (more rules, progression, permutation).
3. **Largest Performance Gap:** The most substantial difference appears in the "Logic" problem category (subplot a) and the "Aligned" condition within logic problems (subplot e).
4. **Human Variability:** The error bars (likely standard error or confidence intervals) for Human performance are generally larger than those for GPT-3, indicating greater variability in human responses.
5. **Notable Crossover:** In subplot d, for "3 unique rules," Human performance (≈0.48) appears slightly higher than GPT-3 performance (≈0.38), which is an exception to the overall trend.
### Interpretation
The data suggests that GPT-3 possesses a robust capability for solving structured reasoning tasks, outperforming human participants in this specific experimental setup. The consistent decline in accuracy with increasing complexity for both groups validates the experimental design's difficulty scaling. The particularly large gap in "Logic" problems indicates that GPT-3 may have a stronger grasp of abstract, formal logical structures compared to the tested human cohort. The crossover in subplot d (3 unique rules) is a critical outlier, suggesting a potential specific weakness in GPT-3's generative reasoning when faced with a high number of concurrent, unique rules, where human reasoning, while still challenged, may employ different strategies that are slightly more effective in that narrow case. Overall, the charts demonstrate GPT-3's advanced but not infallible reasoning abilities, with performance sensitive to problem structure and complexity.