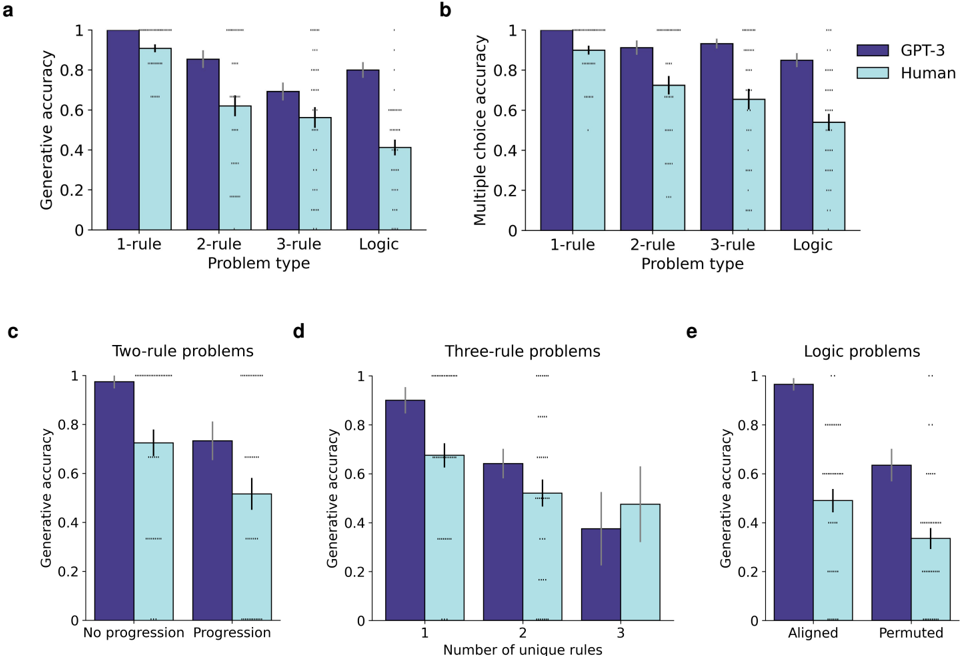
## Bar Chart Series: GPT-3 vs Human Performance Across Problem Types
### Overview
The image contains five grouped bar charts (a-e) comparing generative accuracy and multiple choice accuracy between GPT-3 (purple) and humans (light blue) across different problem types. Charts focus on rule-based logic problems with varying complexity (1-rule to 3-rule) and logic problem configurations (aligned/permuted). Error bars indicate standard deviation.
### Components/Axes
**Common Elements:**
- **X-axis**: Problem types (1-rule, 2-rule, 3-rule, Logic)
- **Y-axis**: Accuracy metrics (0-1 scale)
- **Legend**:
- Purple = GPT-3
- Light blue = Human
- **Error bars**: Standard deviation (vertical lines with caps)
**Chart-Specific Axes:**
- **a/b**: Generative/Multiple choice accuracy
- **c**: Two-rule problem progression (No progression/Progression)
- **d**: Three-rule problem complexity (1-3 unique rules)
- **e**: Logic problem alignment (Aligned/Permuted)
### Detailed Analysis
**Chart a (Generative Accuracy):**
- 1-rule: GPT-3 ~0.95 (±0.03), Human ~0.9 (±0.05)
- 2-rule: GPT-3 ~0.85 (±0.04), Human ~0.65 (±0.07)
- 3-rule: GPT-3 ~0.7 (±0.06), Human ~0.55 (±0.08)
- Logic: GPT-3 ~0.8 (±0.05), Human ~0.4 (±0.09)
**Chart b (Multiple Choice Accuracy):**
- 1-rule: GPT-3 ~0.98 (±0.02), Human ~0.92 (±0.04)
- 2-rule: GPT-3 ~0.95 (±0.03), Human ~0.78 (±0.06)
- 3-rule: GPT-3 ~0.9 (±0.05), Human ~0.7 (±0.08)
- Logic: GPT-3 ~0.85 (±0.04), Human ~0.55 (±0.1)
**Chart c (Two-Rule Progression):**
- No progression: GPT-3 ~0.98 (±0.02), Human ~0.75 (±0.06)
- Progression: GPT-3 ~0.8 (±0.05), Human ~0.5 (±0.07)
**Chart d (Three-Rule Complexity):**
- 1 unique rule: GPT-3 ~0.9 (±0.04), Human ~0.7 (±0.06)
- 2 unique rules: GPT-3 ~0.65 (±0.07), Human ~0.5 (±0.08)
- 3 unique rules: GPT-3 ~0.4 (±0.09), Human ~0.45 (±0.1)
**Chart e (Logic Alignment):**
- Aligned: GPT-3 ~0.95 (±0.03), Human ~0.55 (±0.07)
- Permuted: GPT-3 ~0.65 (±0.06), Human ~0.35 (±0.08)
### Key Observations
1. **Performance Gradient**: GPT-3 maintains >90% accuracy in 1-rule problems but drops to ~65% in 3-rule problems, while humans decline from ~90% to ~45%.
2. **Logic Problem Sensitivity**: Humans show 50% accuracy drop in permuted logic problems vs aligned (vs GPT-3's 30% drop).
3. **Progression Impact**: Human performance in two-rule problems improves by 33% with progression (0.5 → 0.75).
4. **Rule Complexity**: Three-rule problems with 3 unique rules show near-parity between GPT-3 (40%) and humans (45%), suggesting similar difficulty thresholds.
### Interpretation
The data demonstrates GPT-3's superior performance in rule-based reasoning across all problem types, with performance degradation correlating with problem complexity. Humans show significant sensitivity to problem configuration changes:
- **Progression Matters**: Incremental learning (progression) improves human performance by 33% in two-rule problems.
- **Alignment Criticality**: Logic problems require strict rule alignment for human performance (55% aligned vs 35% permuted).
- **Complexity Thresholds**: Both systems struggle equally with three-rule problems involving 3 unique rules, suggesting this represents a cognitive/computational difficulty ceiling.
The results imply that while GPT-3 maintains consistent rule application, humans require explicit problem structure (alignment, progression) to perform effectively. The near-parity in three-rule problems suggests both systems face similar challenges with highly complex logical reasoning tasks.