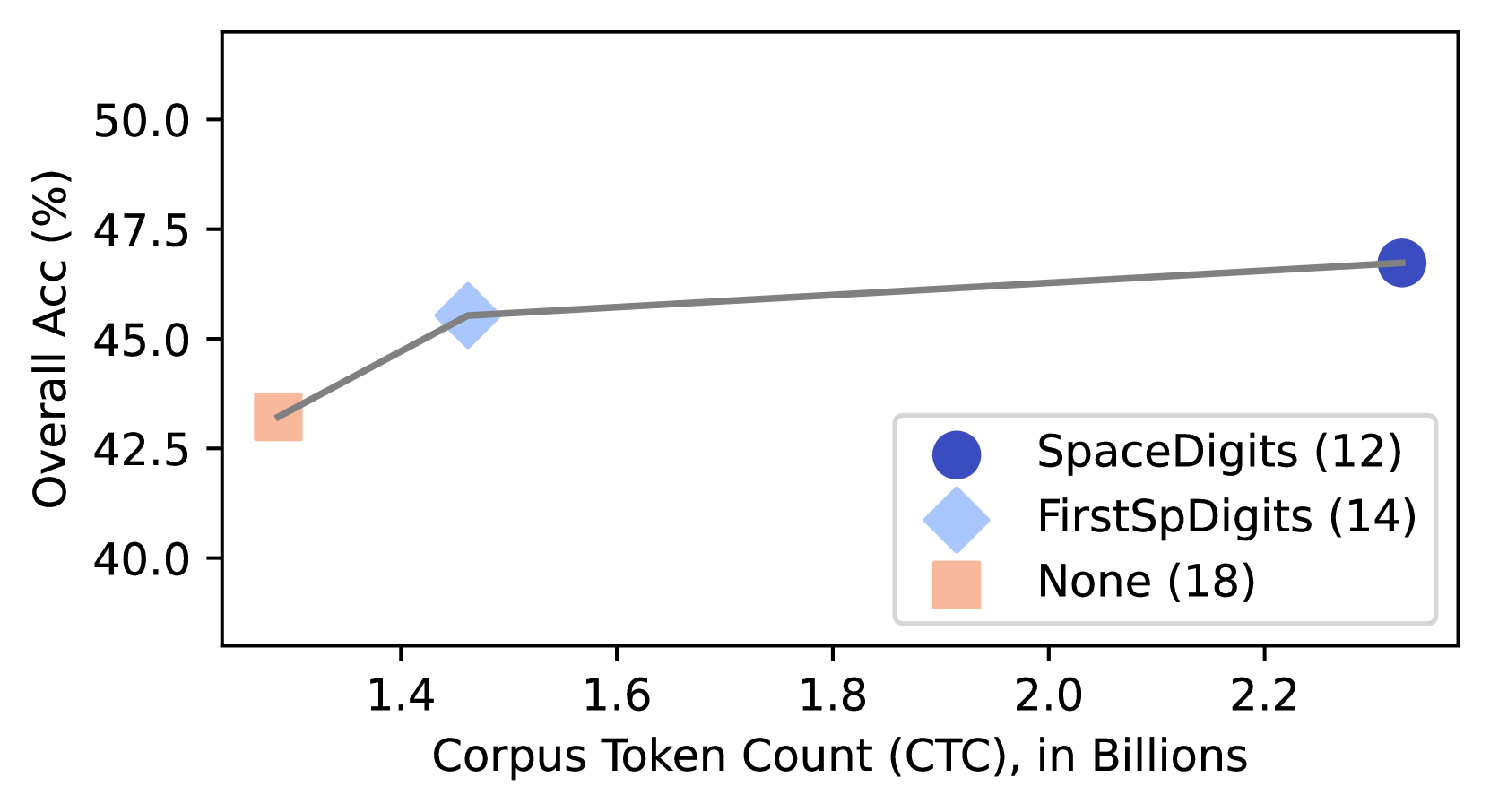
## Line Chart: Overall Accuracy vs. Corpus Token Count
### Overview
The image is a line chart comparing the overall accuracy (%) against the corpus token count (CTC) in billions for three different configurations: "SpaceDigits (12)", "FirstSpDigits (14)", and "None (18)". The chart shows how the overall accuracy changes as the corpus token count increases for each configuration.
### Components/Axes
* **X-axis:** Corpus Token Count (CTC), in Billions. Scale ranges from approximately 1.3 to 2.3, with tick marks at 1.4, 1.6, 1.8, 2.0, and 2.2.
* **Y-axis:** Overall Acc (%), ranging from 40.0 to 50.0, with tick marks at 40.0, 42.5, 45.0, 47.5, and 50.0.
* **Legend:** Located on the right side of the chart, it identifies the three configurations:
* Blue circle: SpaceDigits (12)
* Light blue diamond: FirstSpDigits (14)
* Light orange square: None (18)
### Detailed Analysis
* **SpaceDigits (12):** Represented by a blue circle. The line starts at approximately (1.4, 45.5) and ends at approximately (2.3, 47.0). The trend is slightly upward.
* **FirstSpDigits (14):** Represented by a light blue diamond. The line starts at approximately (1.4, 45.5). This data point only has one value.
* **None (18):** Represented by a light orange square. The line starts at approximately (1.3, 43.5). This data point only has one value.
### Key Observations
* The overall accuracy generally increases with the corpus token count.
* The "SpaceDigits (12)" configuration has a slightly higher overall accuracy than the other two configurations.
* The "None (18)" configuration has the lowest overall accuracy.
### Interpretation
The chart suggests that increasing the corpus token count generally improves the overall accuracy of the model. The "SpaceDigits (12)" configuration appears to perform slightly better than the "FirstSpDigits (14)" and "None (18)" configurations, indicating that including space digits in the corpus may lead to better performance. The "None (18)" configuration performs the worst, suggesting that including some form of digit representation is beneficial. The numbers in parentheses next to each configuration name might represent the number of training epochs or another relevant parameter.