\n
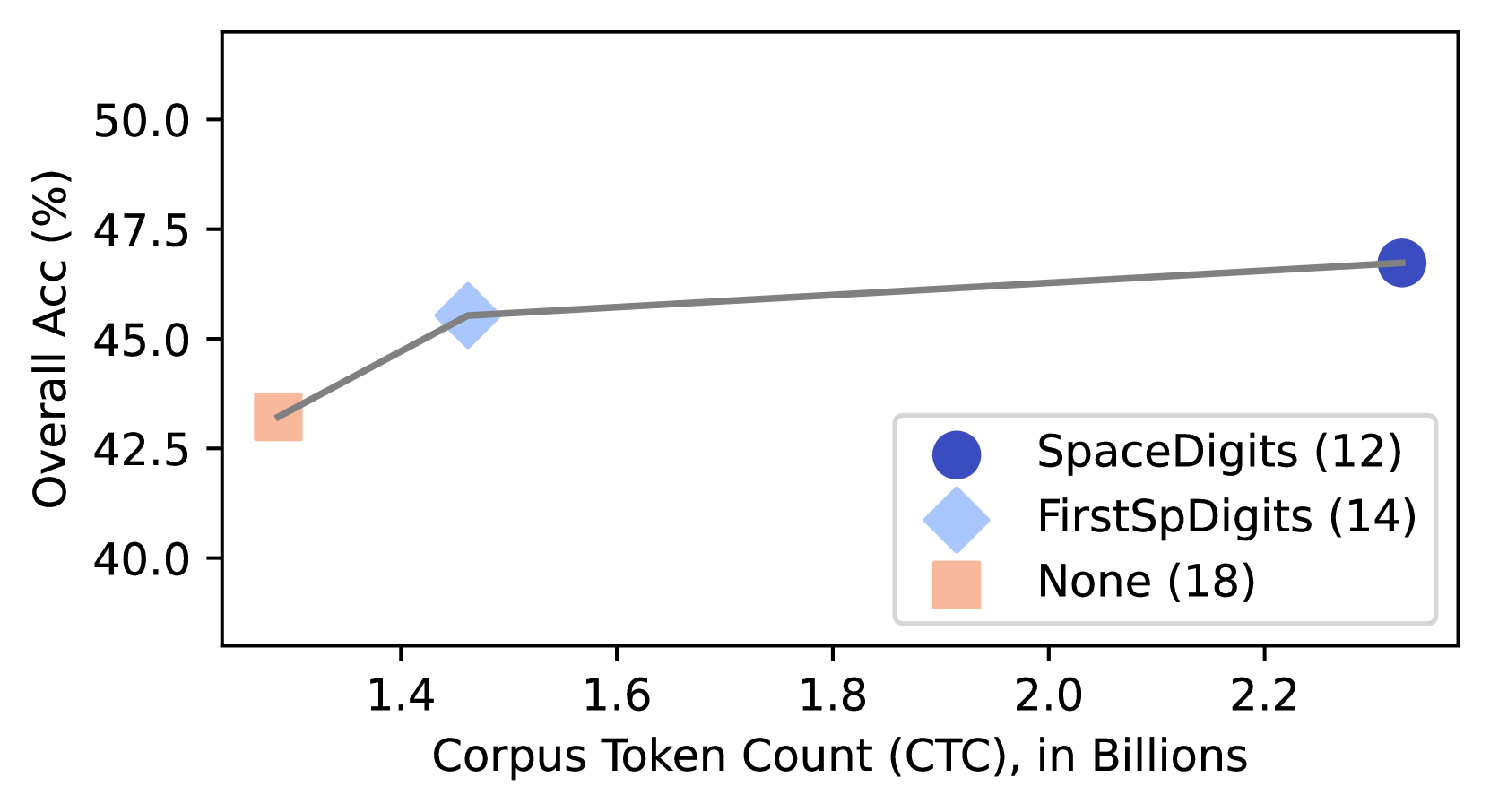
## Line Chart: Overall Accuracy vs. Corpus Token Count
### Overview
This line chart depicts the relationship between Corpus Token Count (CTC) and Overall Accuracy (Acc) for three different configurations: SpaceDigits, FirstSpDigits, and None. The x-axis represents the Corpus Token Count in billions, and the y-axis represents the Overall Accuracy as a percentage. Each configuration is represented by a distinct line with corresponding markers.
### Components/Axes
* **X-axis Title:** Corpus Token Count (CTC), in Billions
* **X-axis Scale:** Ranges from approximately 1.3 to 2.3 billion tokens.
* **Y-axis Title:** Overall Acc (%)
* **Y-axis Scale:** Ranges from approximately 41.5% to 50.5%.
* **Legend:** Located in the top-right corner.
* **SpaceDigits (12):** Represented by a dark blue circle.
* **FirstSpDigits (14):** Represented by a light blue triangle.
* **None (18):** Represented by an orange square.
### Detailed Analysis
* **SpaceDigits (Dark Blue):** The line slopes upward initially, then plateaus.
* At approximately 1.4 billion tokens, the accuracy is around 43.2%.
* At approximately 2.2 billion tokens, the accuracy is around 46.5%.
* **FirstSpDigits (Light Blue):** The line shows a moderate increase, then levels off.
* At approximately 1.4 billion tokens, the accuracy is around 45.2%.
* At approximately 2.2 billion tokens, the accuracy is around 46.2%.
* **None (Orange):** The line shows a slight increase, then remains relatively flat.
* At approximately 1.4 billion tokens, the accuracy is around 42.5%.
* At approximately 2.2 billion tokens, the accuracy is around 43.5%.
### Key Observations
* SpaceDigits consistently exhibits the lowest accuracy across all token counts.
* FirstSpDigits consistently shows the highest accuracy.
* The accuracy improvements for all configurations diminish as the Corpus Token Count increases beyond approximately 1.8 billion tokens.
* The differences in accuracy between the configurations are relatively small, particularly at higher token counts.
### Interpretation
The data suggests that incorporating either SpaceDigits or FirstSpDigits into the model improves overall accuracy compared to using none. However, the benefit of these configurations appears to plateau as the size of the corpus increases. This could indicate that the information provided by SpaceDigits and FirstSpDigits becomes less relevant or is already captured by other features of the model when trained on larger datasets. The relatively small differences in accuracy suggest that these configurations may not be critical for achieving high performance, and other factors likely play a more significant role. The numbers in parentheses after each label (12, 14, 18) likely represent some identifier or parameter associated with each configuration, potentially related to model size or training settings. Further investigation would be needed to understand the specific meaning of these numbers.