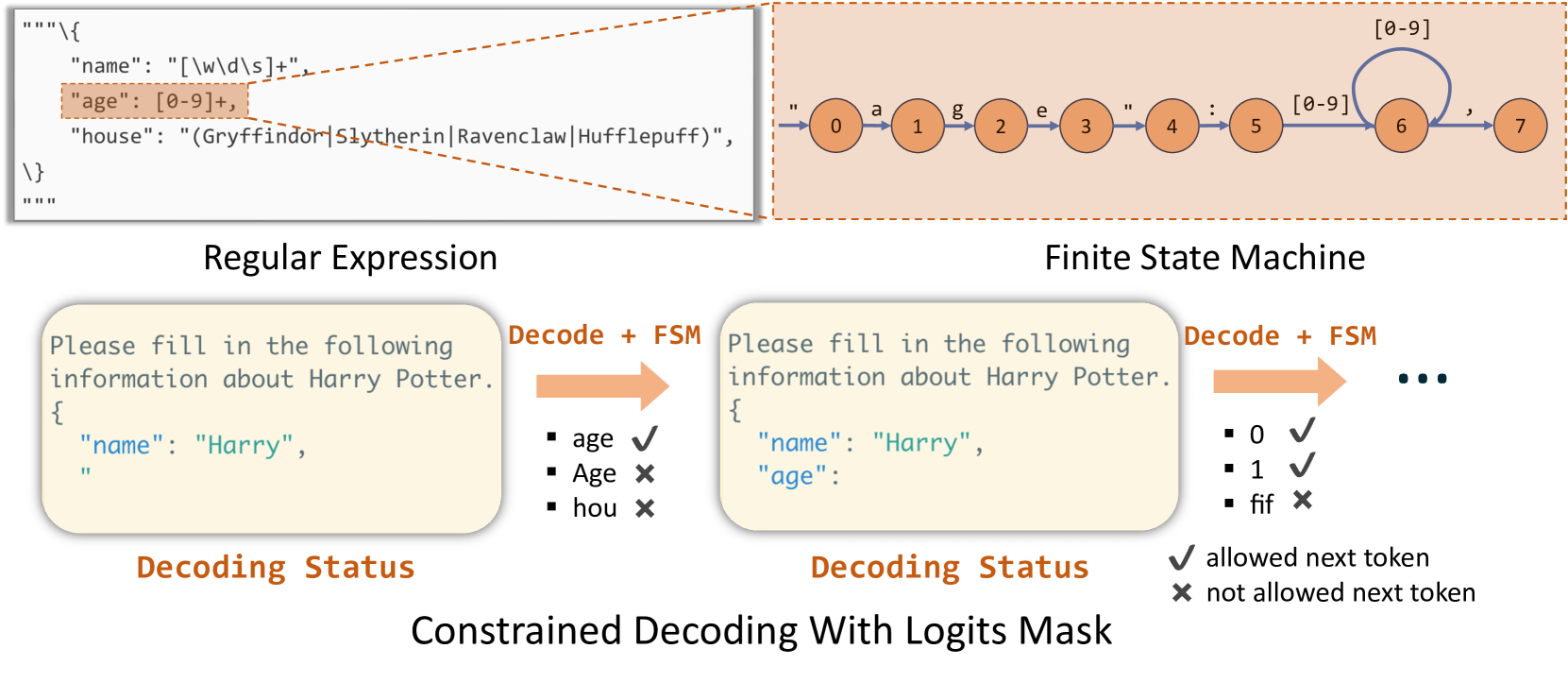
# Technical Document: Constrained Decoding With Logits Mask
This document describes a technical diagram illustrating the process of using Regular Expressions and Finite State Machines (FSM) to constrain the output of a Large Language Model (LLM) during decoding.
## 1. Top Section: Pattern Definition
### Regular Expression (Left)
The diagram shows a JSON-like schema defined using regular expressions:
```json
"""{
"name": "[\w\d\s]+",
"age": [0-9]+,
"house": "(Gryffindor|Slytherin|Ravenclaw|Hufflepuff)",
}
"""
```
The line `"age": [0-9]+,` is highlighted in orange, indicating it is the focus of the subsequent FSM diagram.
### Finite State Machine (Right)
A state transition diagram represents the highlighted regular expression for the "age" field.
* **States:** 8 circular nodes labeled **0** through **7**.
* **Transitions:**
* **0 → 1:** labeled with `"` (double quote)
* **1 → 2:** labeled with `a`
* **2 → 3:** labeled with `g`
* **3 → 4:** labeled with `e`
* **4 → 5:** labeled with `"` (double quote)
* **5 → 6:** labeled with `:` (colon)
* **6 → 6:** self-loop labeled with `[0-9]` (indicates one or more digits)
* **6 → 7:** labeled with `,` (comma)
---
## 2. Bottom Section: Constrained Decoding Flow
The bottom half illustrates the step-by-step "Decoding Status" as the model generates text, using the FSM to mask invalid tokens.
### Step 1: Initial Decoding Status
* **Current Text:**
```text
Please fill in the following information about Harry Potter.
{
"name": "Harry",
"
```
* **Action (Decode + FSM):** An orange arrow points to a validation list.
* **Token Validation:**
* `age` ✔ (Allowed: matches the next expected sequence in the schema)
* `Age` ✘ (Not allowed: case-sensitive mismatch)
* `hou` ✘ (Not allowed: "house" is not the next expected key)
### Step 2: Updated Decoding Status
* **Current Text:**
```text
Please fill in the following information about Harry Potter.
{
"name": "Harry",
"age":
```
* **Action (Decode + FSM):** An orange arrow points to a validation list for the value of the "age" field.
* **Token Validation:**
* `0` ✔ (Allowed: matches `[0-9]`)
* `1` ✔ (Allowed: matches `[0-9]`)
* `fif` ✘ (Not allowed: alphabetical characters are not permitted in the numeric age field)
### Legend
* **✔**: allowed next token
* **✘**: not allowed next token
---
## 3. Summary of Logic
The diagram demonstrates **Constrained Decoding With Logits Masking**. By converting a schema (Regular Expression) into a Finite State Machine, the system can determine exactly which tokens are valid at any given point in the generation. Tokens that do not match the FSM transitions are masked (assigned a probability of zero), ensuring the LLM output strictly adheres to the predefined JSON format.