\n
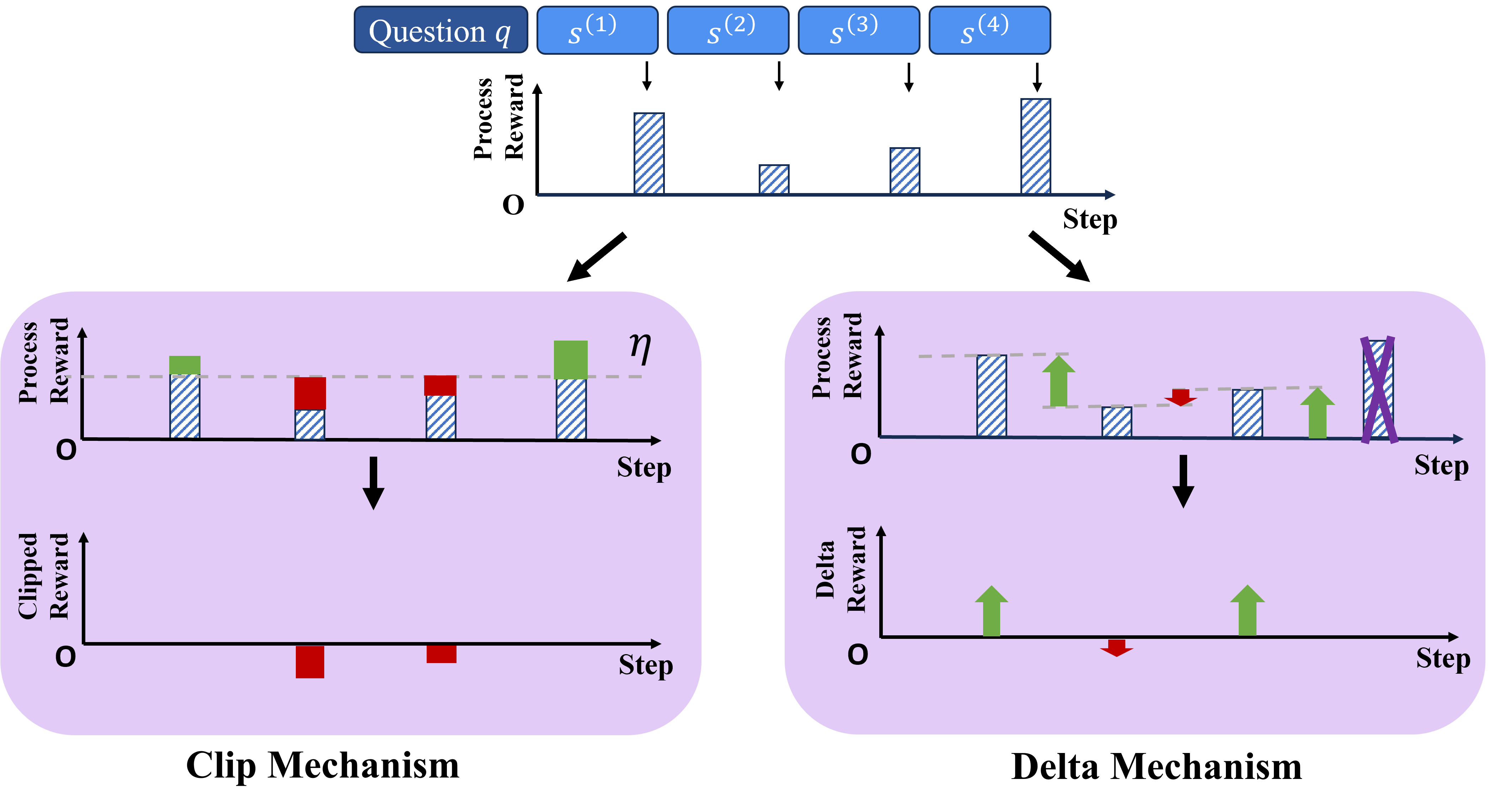
## Diagram: Reward Clipping and Delta Mechanisms
### Overview
This diagram illustrates two mechanisms for reward shaping in a reinforcement learning context: a "Clip Mechanism" and a "Delta Mechanism". Both mechanisms aim to modify the process reward signal over a series of steps (s1 to s4) to improve learning stability or performance. The diagram visually demonstrates how the process reward is transformed into a clipped reward or a delta reward, respectively.
### Components/Axes
The diagram consists of several key components:
* **Question q:** A label at the top-center indicating an initial question or query.
* **States s(1) to s(4):** Four states, labeled sequentially from s(1) to s(4), positioned horizontally above the first set of reward bars.
* **Step:** The x-axis label for all charts, representing the progression of steps.
* **Process Reward:** The y-axis label for the initial reward bars, indicating the original reward signal.
* **Clipped Reward:** The y-axis label for the bottom-left chart, representing the reward after clipping.
* **Delta Reward:** The y-axis label for the bottom-right chart, representing the reward difference.
* **η (eta):** A symbol positioned above the middle chart, likely representing a threshold or parameter.
* **Arrows:** Arrows indicate the flow of transformation from the process reward to the clipped/delta reward.
* **Reward Bars:** Vertical bars representing the magnitude of the reward at each step. The bars are patterned to indicate the portion of the reward that is retained or modified.
* **Clip Mechanism:** Label at the bottom-left, indicating the name of the first mechanism.
* **Delta Mechanism:** Label at the bottom-right, indicating the name of the second mechanism.
### Detailed Analysis or Content Details
**Top Row: Process Reward**
The top row shows the initial "Process Reward" across four steps (s1 to s4). The approximate values of the reward bars are as follows:
* s(1): Reward ≈ 2.5
* s(2): Reward ≈ 1.5
* s(3): Reward ≈ 3.0
* s(4): Reward ≈ 1.0
**Clip Mechanism (Left Column)**
1. **Process Reward (Middle Row):** The middle row shows the "Process Reward" with a patterned overlay, indicating a clipping operation. The approximate values are the same as the top row. The symbol η is present, suggesting a clipping threshold.
2. **Clipped Reward (Bottom Row):** The bottom row shows the "Clipped Reward". The reward is clipped at a certain level.
* s(1): Clipped Reward ≈ 2.5
* s(2): Clipped Reward ≈ 1.5
* s(3): Clipped Reward ≈ 2.5 (appears to be clipped down from 3.0)
* s(4): Clipped Reward ≈ 1.0
**Delta Mechanism (Right Column)**
1. **Process Reward (Middle Row):** The middle row shows the "Process Reward" with a patterned overlay. The approximate values are the same as the top row.
2. **Delta Reward (Bottom Row):** The bottom row shows the "Delta Reward". The reward is represented as a difference from the previous step.
* s(1): Delta Reward ≈ 2.5 (initial value)
* s(2): Delta Reward ≈ -1.0 (2.5 - 1.5 = 1.0, but shown as negative)
* s(3): Delta Reward ≈ +1.5 (1.5 - 3.0 = -1.5, but shown as positive)
* s(4): Delta Reward ≈ -2.0 (3.0 - 1.0 = 2.0, but shown as negative)
### Key Observations
* The Clip Mechanism appears to limit the maximum reward value, preventing large reward spikes.
* The Delta Mechanism focuses on the *change* in reward, potentially emphasizing learning from transitions rather than absolute reward values.
* The Delta Mechanism shows negative values, which is unusual. The values are calculated as the difference between the current and previous reward, but the sign is reversed.
* The reward values in the top row are not consistent, varying between approximately 1.0 and 3.0.
### Interpretation
The diagram illustrates two different approaches to reward shaping. The Clip Mechanism aims to stabilize learning by preventing excessively large rewards from dominating the learning process. This can be useful in environments where rewards are sparse or noisy. The Delta Mechanism, on the other hand, focuses on the *change* in reward, which can be helpful in environments where the agent needs to learn to predict future rewards based on current actions.
The reversed sign of the Delta Reward is a notable anomaly. It suggests that the mechanism might be designed to penalize decreases in reward or reward increases. This could be a specific design choice to encourage exploration or to avoid getting stuck in local optima.
The relationship between the "Question q" and the states s(1) to s(4) suggests that the agent is interacting with an environment and receiving rewards based on its actions in response to the question. The reward shaping mechanisms are then applied to these rewards to guide the agent's learning process. The diagram provides a high-level conceptual overview of these mechanisms, without specifying the exact algorithms or parameters used.