TECHNICAL ASSET FINGERPRINT
4e28d956bd04088fba70bcd0
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
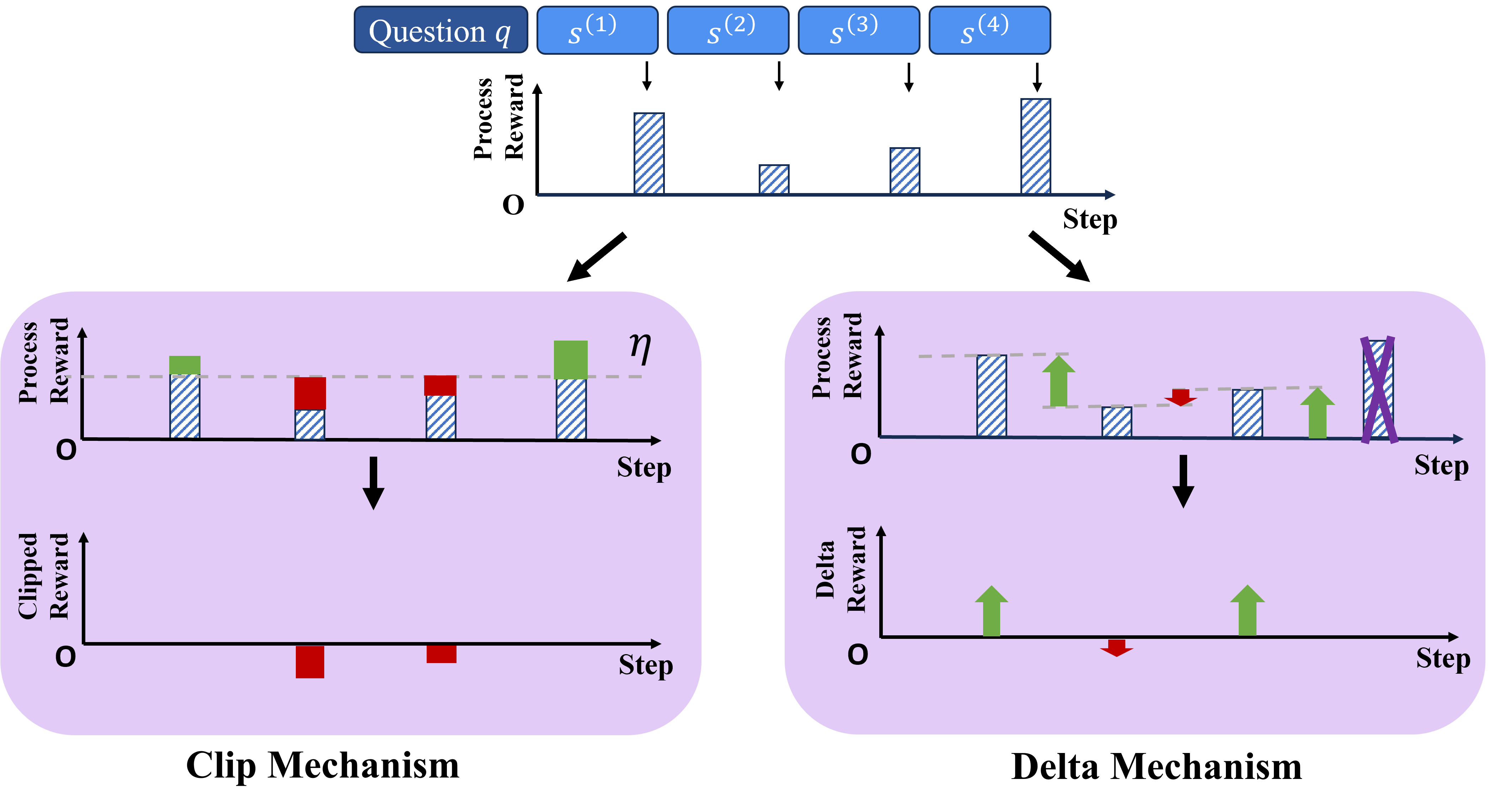
## Diagram: Reward Processing Mechanisms (Clip vs. Delta)
### Overview
The image is a technical diagram illustrating and comparing two distinct mechanisms for processing step-wise rewards in a sequential decision-making or learning context, likely within reinforcement learning or AI training. The diagram is divided into a top section showing an initial reward sequence and two main panels below, each detailing one mechanism: the "Clip Mechanism" on the left and the "Delta Mechanism" on the right.
### Components/Axes
**Top Section (Input Sequence):**
* **Header Elements:** A blue box labeled "Question q" followed by four blue boxes labeled `s⁽¹⁾`, `s⁽²⁾`, `s⁽³⁾`, `s⁽⁴⁾`, representing sequential steps or states.
* **Chart:** A bar chart with:
* **Y-axis:** Labeled "Process Reward" (vertical text).
* **X-axis:** Labeled "Step".
* **Data:** Four blue, diagonally striped bars of varying heights corresponding to steps 1 through 4. The bar for step 1 is the tallest, step 2 is the shortest, step 3 is of medium height, and step 4 is the second tallest.
* **Flow:** Two black arrows point downwards from this top chart, one leading to the left panel (Clip Mechanism) and one to the right panel (Delta Mechanism).
**Left Panel: Clip Mechanism**
* **Background:** Light purple rounded rectangle.
* **Top Sub-chart ("Process Reward"):**
* **Y-axis:** "Process Reward".
* **X-axis:** "Step".
* **Threshold:** A horizontal dashed grey line labeled with the Greek letter η (eta) on the right side.
* **Data Bars:** The original blue striped bars are shown. Bars exceeding the η threshold (steps 1 and 4) have a solid green segment above the line. Bars below the threshold (steps 2 and 3) have a solid red segment on top.
* **Bottom Sub-chart ("Clipped Reward"):**
* **Y-axis:** "Clipped Reward".
* **X-axis:** "Step".
* **Data:** Only solid red bars are present, located at steps 2 and 3. These bars are positioned below the zero line, indicating negative values. No bars are shown for steps 1 and 4.
* **Label:** The text "Clip Mechanism" is centered below this panel.
**Right Panel: Delta Mechanism**
* **Background:** Light purple rounded rectangle.
* **Top Sub-chart ("Process Reward"):**
* **Y-axis:** "Process Reward".
* **X-axis:** "Step".
* **Data & Annotations:** The original blue striped bars are shown. Each bar is annotated with an arrow:
* Step 1: A green upward-pointing arrow.
* Step 2: A red downward-pointing arrow.
* Step 3: A green upward-pointing arrow.
* Step 4: The bar is crossed out with a large purple "X".
* **Reference Line:** A horizontal dashed grey line is present, aligned with the top of the bar for step 1.
* **Bottom Sub-chart ("Delta Reward"):**
* **Y-axis:** "Delta Reward".
* **X-axis:** "Step".
* **Data:** Arrows represent the reward delta:
* Step 1: A green upward-pointing arrow (positive delta).
* Step 2: A red downward-pointing arrow (negative delta).
* Step 3: A green upward-pointing arrow (positive delta).
* Step 4: No arrow or bar is present.
* **Label:** The text "Delta Mechanism" is centered below this panel.
### Detailed Analysis
**Clip Mechanism Flow:**
1. **Input:** The sequence of four process rewards.
2. **Clipping Operation:** A threshold `η` is applied. Rewards above `η` are "clipped" to `η` (the green segments represent the clipped-off portion). Rewards below `η` are left as-is, but the diagram highlights them in red for the next stage.
3. **Output ("Clipped Reward"):** The final output only shows negative reward signals (red bars) for the steps where the original reward was below the threshold (steps 2 and 3). Steps with rewards above the threshold (1 and 4) produce no output signal in this chart.
**Delta Mechanism Flow:**
1. **Input:** The same sequence of four process rewards.
2. **Delta Calculation:** The mechanism appears to compute a change or advantage relative to a reference (the dashed line from step 1's reward).
* Step 1: Serves as the reference (delta = 0, but marked with a green up arrow, possibly indicating a positive baseline).
* Step 2: Reward is lower than the reference → negative delta (red down arrow).
* Step 3: Reward is higher than the reference → positive delta (green up arrow).
* Step 4: The reward is crossed out, suggesting it is ignored or treated specially, resulting in no delta output.
3. **Output ("Delta Reward"):** The output chart visualizes these computed deltas as directional arrows (green for positive, red for negative).
### Key Observations
* **Divergent Outputs:** The two mechanisms produce fundamentally different final reward signals from the same input sequence. The Clip Mechanism outputs only negative, threshold-based penalties. The Delta Mechanism outputs signed (positive/negative) change signals.
* **Handling of High Rewards:** The Clip Mechanism caps high rewards (steps 1 & 4) and generates no output for them. The Delta Mechanism uses the first high reward as a reference and ignores the last one (step 4 is crossed out).
* **Visual Coding:** Consistent color coding is used: blue stripes for original data, green for positive/above-threshold, red for negative/below-threshold, and purple for exclusion.
* **Spatial Layout:** The legend (color meaning) is embedded directly in the charts via the colored bars and arrows, not in a separate box. The threshold `η` is placed in the top-right of its sub-chart.
### Interpretation
This diagram contrasts two philosophies for shaping reward signals in learning systems:
1. **Clip Mechanism (Conservative/Penalty-Focused):** It acts as a filter that only generates a training signal (a penalty) when performance falls below a predefined acceptable threshold (`η`). This could be used to discourage poor steps without being influenced by how exceptionally good a step is. It simplifies the reward landscape to "acceptable" vs. "unacceptable."
2. **Delta Mechanism (Comparative/Advantage-Focused):** It computes a relative advantage or disadvantage compared to a baseline (step 1's reward). This provides richer, signed feedback: "this step was better/worse than our reference." The crossing out of step 4 is a critical anomaly; it suggests the mechanism may discard rewards that are too high or outliers, possibly to prevent reward hacking or to maintain stable learning by focusing on incremental changes.
**Underlying Message:** The choice between mechanisms involves a trade-off. The Clip Mechanism is simpler and may lead to more stable but potentially less nuanced learning. The Delta Mechanism provides more informative gradient-like signals but requires careful handling of baselines and outliers (as shown by the crossed-out step 4). The diagram effectively argues that how intermediate rewards are processed significantly alters the feedback a learning agent receives.
DECODING INTELLIGENCE...