## Workflow Diagram: Dreamcatcher Factuality Ranking and LLM Optimization
### Overview
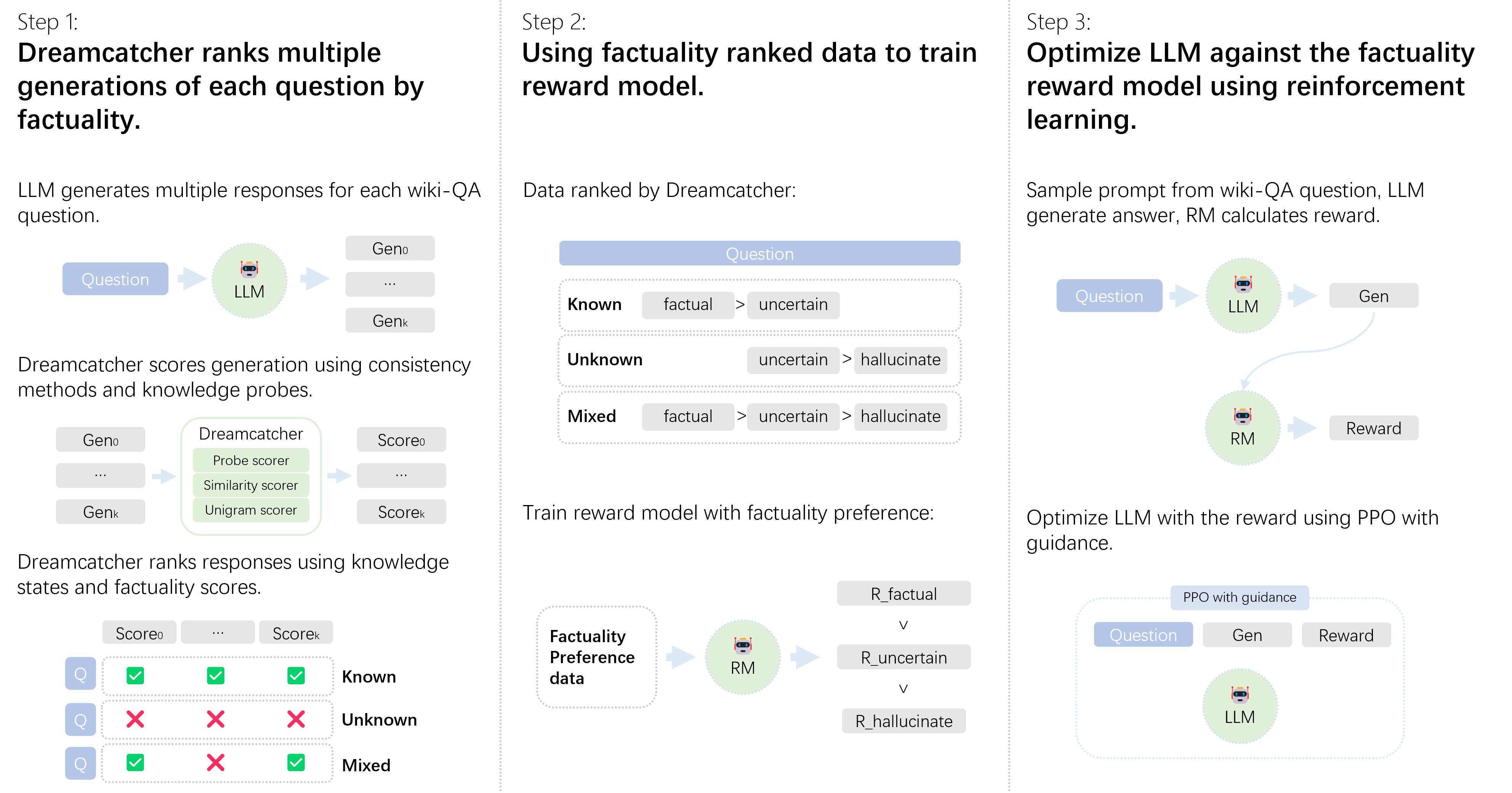
The image presents a three-step workflow diagram illustrating how Dreamcatcher ranks multiple generations of questions by factuality, trains a reward model using factuality-ranked data, and optimizes a Large Language Model (LLM) against the factuality reward model using reinforcement learning.
### Components/Axes
**Step 1: Dreamcatcher ranks multiple generations of each question by factuality.**
* **Input:** Question (represented by a blue rounded rectangle).
* **Process:** LLM (represented by an icon of a robot head within a green circle) generates multiple responses.
* **Output:** Generations (Geno, ..., Genk).
* **Scoring:** Dreamcatcher (represented by a green rounded rectangle) scores generations using consistency methods and knowledge probes. The Dreamcatcher block lists "Probe scorer", "Similarity scorer", and "Unigram scorer".
* **Ranking:** Dreamcatcher ranks responses using knowledge states and factuality scores.
* Columns: Score0, ..., Scorek
* Rows:
* Known: All checkmarks (green).
* Unknown: All X marks (red).
* Mixed: Checkmark, X mark, Checkmark.
* **Knowledge States:** Known, Unknown, Mixed.
**Step 2: Using factuality ranked data to train reward model.**
* **Input:** Question (represented by a blue rounded rectangle).
* **Ranking:** Data ranked by Dreamcatcher:
* Known: factual > uncertain
* Unknown: uncertain > hallucinate
* Mixed: factual > uncertain > hallucinate
* **Process:** Train reward model with factuality preference.
* Factuality Preference data (represented by a dotted rounded rectangle) feeds into RM (Reward Model, represented by an icon of a robot head within a green circle).
* The reward model then ranks: R_factual > R_uncertain > R_hallucinate.
**Step 3: Optimize LLM against the factuality reward model using reinforcement learning.**
* **Process:** Sample prompt from wiki-QA question, LLM generates answer, RM calculates reward.
* Question (represented by a blue rounded rectangle) feeds into LLM (represented by an icon of a robot head within a green circle), which generates Gen.
* Gen feeds into RM (represented by an icon of a robot head within a green circle), which calculates Reward.
* **Optimization:** Optimize LLM with the reward using PPO with guidance.
* PPO with guidance (represented by a white rounded rectangle).
* Question (represented by a blue rounded rectangle) and Gen feed into LLM (represented by an icon of a robot head within a green circle), which generates Reward.
### Detailed Analysis or ### Content Details
* **Step 1:** The LLM generates multiple responses (Geno to Genk) for each question. Dreamcatcher then scores these generations using various methods (probe scorer, similarity scorer, unigram scorer) and ranks them based on knowledge states (Known, Unknown, Mixed) and factuality scores.
* **Step 2:** The data ranked by Dreamcatcher is used to train a reward model. The ranking shows the preference order: factual > uncertain > hallucinate for Known and Mixed states, and uncertain > hallucinate for the Unknown state.
* **Step 3:** The LLM is optimized using reinforcement learning. A sample prompt is used to generate an answer, and the reward model calculates a reward. The LLM is then optimized using PPO (Proximal Policy Optimization) with guidance.
### Key Observations
* The workflow emphasizes the importance of factuality in LLM responses.
* Dreamcatcher plays a crucial role in ranking and scoring the generations.
* Reinforcement learning is used to optimize the LLM against the factuality reward model.
### Interpretation
The diagram illustrates a comprehensive approach to improving the factuality of LLM-generated content. By using Dreamcatcher to rank generations and training a reward model based on factuality, the system aims to optimize the LLM to produce more accurate and reliable responses. The use of reinforcement learning with PPO further refines the LLM's behavior to align with the desired factuality preferences. The system prioritizes factual accuracy by penalizing uncertain and hallucinated responses.