\n
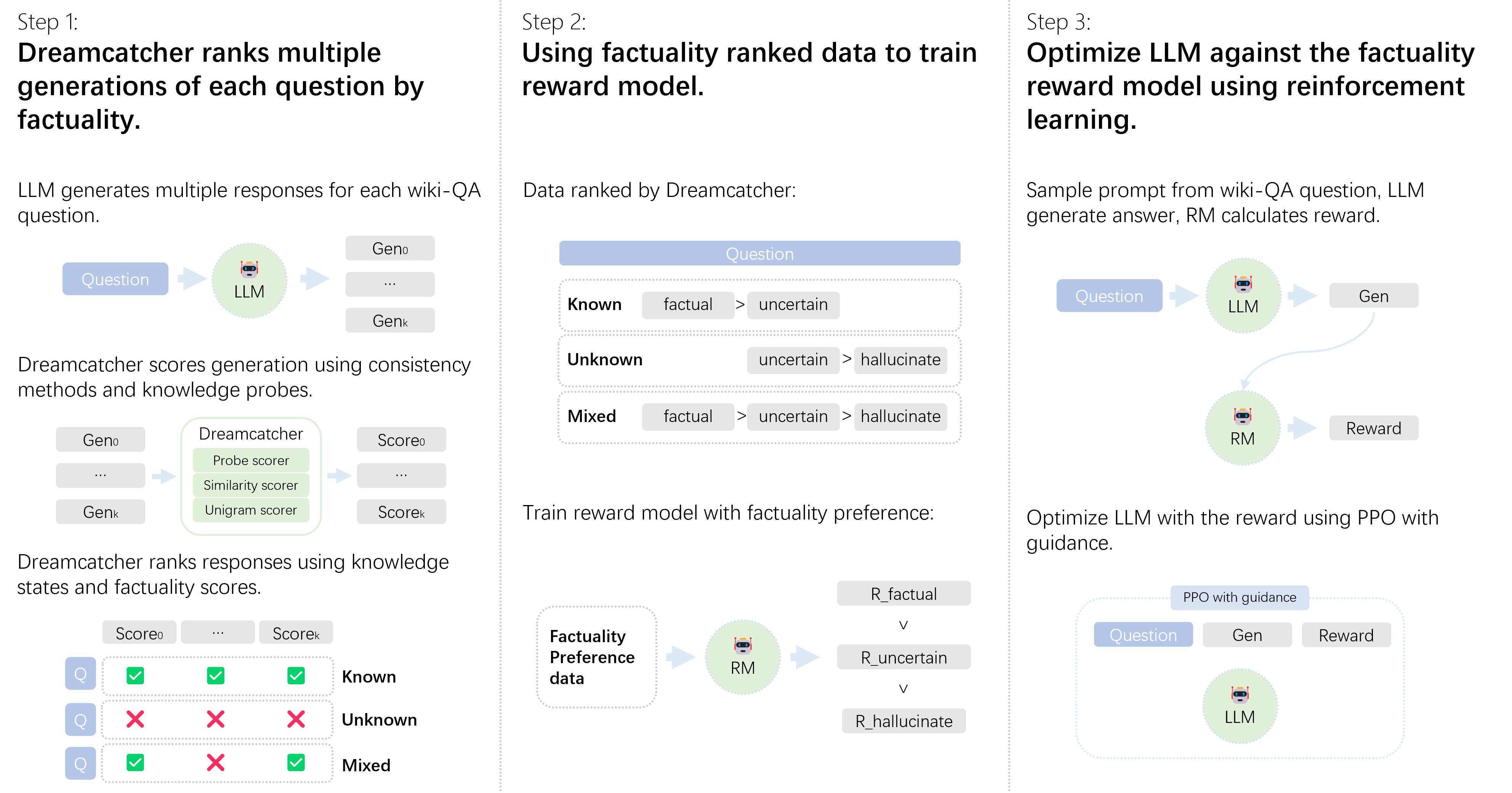
## Diagram: Dreamcatcher Factuality Pipeline
### Overview
This diagram illustrates a three-step pipeline for improving the factuality of Large Language Model (LLM) responses. The pipeline involves ranking LLM generations by factuality using Dreamcatcher, training a reward model based on this ranking, and then optimizing the LLM against the reward model using reinforcement learning.
### Components/Axes
The diagram is divided into three sequential steps, labeled "Step 1", "Step 2", and "Step 3". Each step contains a visual representation of the process, with boxes representing components (LLM, Dreamcatcher, Reward Model, etc.) and arrows indicating the flow of information. Key terms are "factual", "uncertain", and "hallucinate".
### Detailed Analysis or Content Details
**Step 1: Dreamcatcher ranks multiple generations of each question by factuality.**
* **LLM generates multiple responses:** A "Question" input feeds into an "LLM" (Large Language Model) which produces multiple generations labeled "Gen0", "Gen1", "Genk".
* **Dreamcatcher scores generation:** "Gen0" and "Gen1" are fed into "Dreamcatcher" which uses "Probe scorer", "Similarity scorer", and "Unigram scorer" to produce a "Score".
* **Dreamcatcher ranks responses:** A table is shown with "Preference" (represented by a question mark "Q") and "Score". The table has three rows:
* Known: Q, Checkmark, Checkmark
* Unknown: Q, Cross, Cross
* Mixed: Q, Checkmark, Cross
**Step 2: Using factuality ranked data to train reward model.**
* **Data ranked by Dreamcatcher:** A "Question" input is processed by Dreamcatcher, resulting in categories: "Known", "Unknown", and "Mixed".
* **Factuality Ranking:** The categories are ranked by factuality:
* Known: factual > uncertain
* Unknown: uncertain > hallucinate
* Mixed: factual > uncertain > hallucinate
* **Train reward model:** "Factuality Preference data" is used to train a "Reward Model" (RM).
* **Reward Model Preference:** The Reward Model has preferences:
* R_factual >
* R_uncertain >
* R_hallucinate
**Step 3: Optimize LLM against the factuality reward model using reinforcement learning.**
* **Sample prompt:** A "Question" input is fed into an "LLM" which generates "Gen".
* **Reward Calculation:** "Gen" and the "Question" are fed into a "Reward Model" (RM) which calculates a "Reward".
* **LLM Optimization:** The LLM is optimized using PPO (Proximal Policy Optimization) with guidance, utilizing the "Question", "Gen", and "Reward".
### Key Observations
* The diagram emphasizes a clear progression from generation to evaluation to optimization.
* The factuality ranking in Step 2 provides a hierarchical structure for categorizing responses.
* The use of reinforcement learning in Step 3 suggests an iterative process of improvement.
* The diagram uses visual cues (checkmarks, crosses) to represent positive and negative preferences.
### Interpretation
The diagram outlines a sophisticated approach to enhancing the factuality of LLM outputs. By leveraging Dreamcatcher to rank generations, training a reward model based on these rankings, and then using reinforcement learning to optimize the LLM, the pipeline aims to reduce the generation of uncertain or hallucinatory responses. The ranking system (factual > uncertain > hallucinate) is central to the process, providing a quantifiable measure of factuality that can be used to guide the LLM's learning. The use of PPO with guidance suggests a controlled optimization process, preventing drastic changes to the LLM's behavior while still promoting factuality. The diagram suggests a focus on not just identifying incorrect information (hallucinations) but also on distinguishing between known facts and uncertain statements.