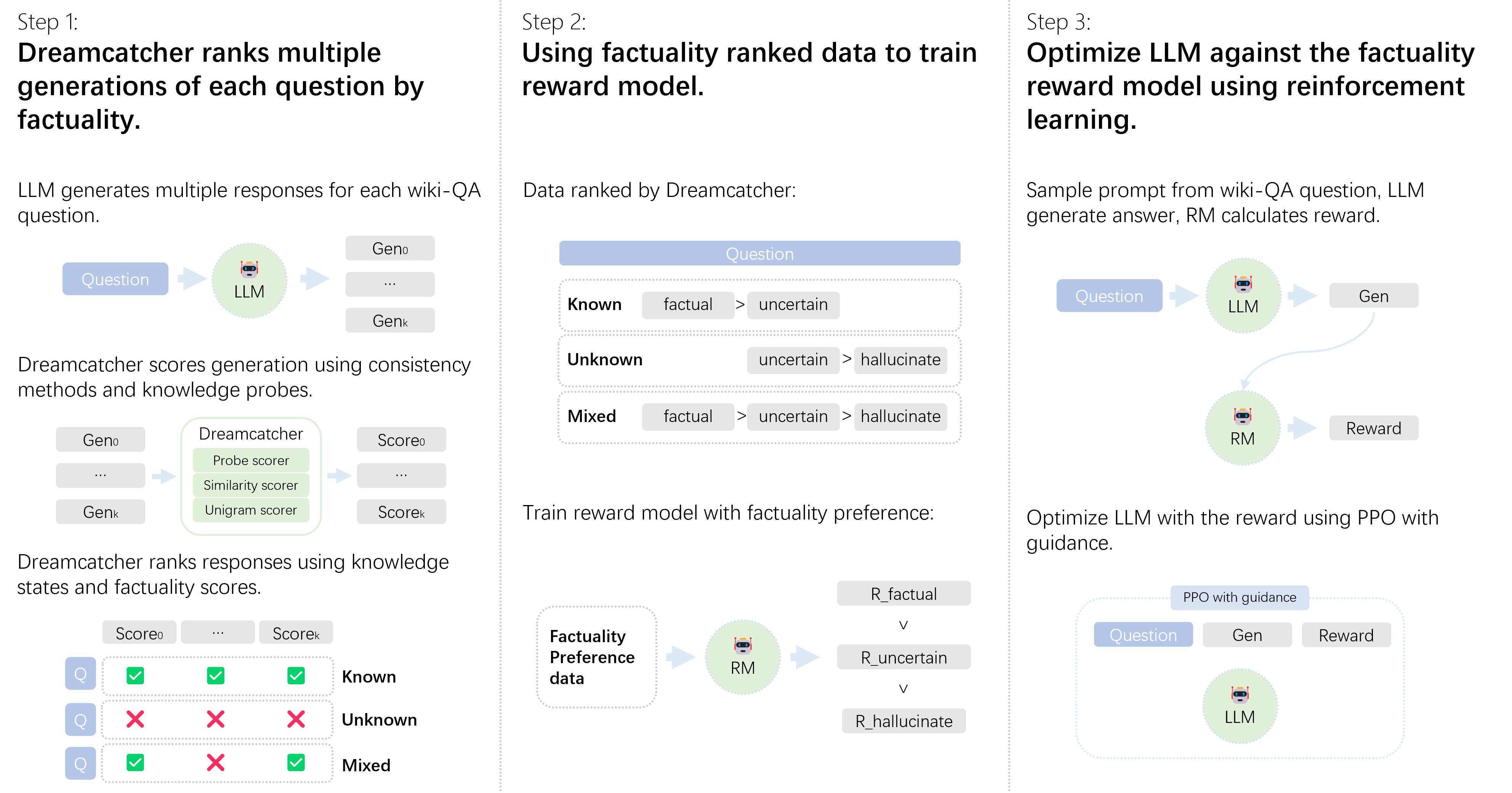
## Flowchart: Three-Step Process for Optimizing LLM with Factuality Reward Model
### Overview
The flowchart illustrates a three-step technical process for optimizing a Large Language Model (LLM) using factuality-aware reinforcement learning. It combines automated response generation, factuality ranking, and reward model training to improve LLM outputs.
### Components/Axes
1. **Step 1: Dreamcatcher Ranks Multiple Generations by Factuality**
- **Input**: Wiki-QA question
- **LLM**: Generates multiple responses (Gen₀ to Genₖ)
- **Dreamcatcher**: Scores responses using:
- Consistency methods
- Knowledge probes (Probe scorer, Similarity scorer, Unigram scorer)
- **Output**: Responses ranked by knowledge states and factuality scores (Score₀ to Scoreₖ)
2. **Step 2: Train Reward Model with Factuality Preference Data**
- **Input**: Dreamcatcher-ranked data categorized as:
- Known (factual > uncertain)
- Unknown (uncertain > hallucinate)
- Mixed (mixed factuality states)
- **Reward Model (RM)**: Trained using:
- Factuality preference data
- Reward vectors (R_factual, R_uncertain, R_hallucinate)
3. **Step 3: Optimize LLM with Reinforcement Learning**
- **Input**: Wiki-QA question
- **Process**:
- LLM generates answer (Gen)
- RM calculates reward based on factuality
- Proximal Policy Optimization (PPO) with guidance refines LLM using reward signal
### Detailed Analysis
#### Step 1: Response Generation & Ranking
- **LLM Output**: Multiple generations (Gen₀ to Genₖ) for each question
- **Dreamcatcher Scoring**:
- Uses three scoring mechanisms (probe, similarity, unigram)
- Ranks responses via knowledge states (Known/Unknown/Mixed)
- Visual representation shows checkmarks (✓) for factual consistency and crosses (✗) for hallucinations
#### Step 2: Reward Model Training
- **Data Categorization**:
- Known: Factual answers with low uncertainty
- Unknown: High uncertainty with potential hallucination
- Mixed: Combination of factual and uncertain elements
- **RM Training**:
- Reward vectors defined for three factuality states
- Direct mapping from Dreamcatcher's rankings to reward signals
#### Step 3: Reinforcement Learning Optimization
- **PPO with Guidance**:
- Uses reward signals from RM to iteratively improve LLM
- Closed-loop system: Question → LLM generation → RM reward → LLM refinement
- Explicit feedback mechanism for factual accuracy
### Key Observations
1. **Hierarchical Process**: Each step builds on the previous one (generation → ranking → optimization)
2. **Factuality Focus**: All components explicitly prioritize factual accuracy over generic response quality
3. **Automated Scoring**: Dreamcatcher's multi-method scoring system enables nuanced factuality assessment
4. **Reinforcement Learning**: PPO with guidance creates continuous improvement loop for LLM
### Interpretation
This process demonstrates a systematic approach to aligning LLMs with factual accuracy requirements through:
1. **Automated Evaluation**: Dreamcatcher's multi-probe system provides comprehensive factuality assessment
2. **Reward Shaping**: The reward model translates factuality scores into actionable training signals
3. **Reinforcement Learning**: PPO with guidance enables efficient parameter optimization based on factuality feedback
The architecture suggests a production-ready system for deploying factually accurate LLMs in domains requiring high reliability, such as scientific QA or legal document analysis. The explicit separation of generation, evaluation, and optimization stages allows for modular improvements and systematic error analysis.