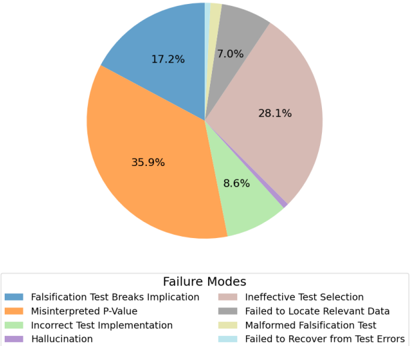
## Pie Chart: Failure Modes
### Overview
The image is a pie chart illustrating the distribution of different failure modes. Each slice represents a specific failure mode, with the size of the slice corresponding to the percentage of occurrences. The legend at the bottom provides the mapping between colors and failure mode descriptions.
### Components/Axes
* **Title:** Failure Modes
* **Categories (Pie Chart Slices):**
* Falsification Test Breaks Implication (Blue)
* Misinterpreted P-Value (Orange)
* Incorrect Test Implementation (Light Green)
* Hallucination (Light Purple)
* Ineffective Test Selection (Light Brown)
* Failed to Locate Relevant Data (Gray)
* Malformed Falsification Test (Light Yellow)
* Failed to Recover from Test Errors (Light Blue)
### Detailed Analysis
The pie chart shows the following distribution of failure modes:
* **Falsification Test Breaks Implication (Blue):** 17.2%
* **Misinterpreted P-Value (Orange):** 35.9%
* **Incorrect Test Implementation (Light Green):** 8.6%
* **Hallucination (Light Purple):** The slice is very small, but it is present.
* **Ineffective Test Selection (Light Brown):** 28.1%
* **Failed to Locate Relevant Data (Gray):** 7.0%
* **Malformed Falsification Test (Light Yellow):** A very small slice, close to 1%.
* **Failed to Recover from Test Errors (Light Blue):** A very small slice, close to 1%.
### Key Observations
* The "Misinterpreted P-Value" failure mode has the highest percentage (35.9%), indicating it is the most frequent type of failure.
* "Ineffective Test Selection" is the second most frequent failure mode, accounting for 28.1% of the failures.
* "Falsification Test Breaks Implication" accounts for 17.2% of the failures.
* "Failed to Locate Relevant Data" accounts for 7.0% of the failures.
* The remaining failure modes ("Incorrect Test Implementation", "Hallucination", "Malformed Falsification Test", and "Failed to Recover from Test Errors") each contribute a relatively small percentage to the overall failure distribution.
### Interpretation
The pie chart provides a clear visualization of the relative frequency of different failure modes. The dominance of "Misinterpreted P-Value" suggests that errors in statistical interpretation are a significant source of failures. "Ineffective Test Selection" also contributes substantially, indicating potential issues with the design or selection of tests. The other failure modes, while less frequent, still contribute to the overall failure rate and should be addressed to improve the system's reliability. The chart highlights areas where targeted interventions, such as improved training on statistical methods and test design, could have the most significant impact on reducing failures.