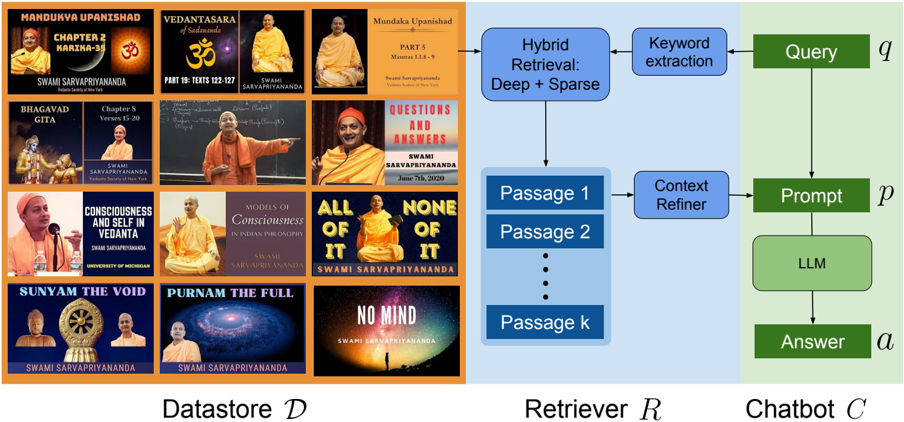
## System Diagram: Chatbot Architecture
### Overview
The image presents a system diagram illustrating the architecture of a chatbot. It details the flow of information from a datastore through a retriever to the chatbot, highlighting key components such as hybrid retrieval, keyword extraction, context refinement, and the large language model (LLM).
### Components/Axes
The diagram is divided into three main sections:
1. **Datastore D**: A collection of video thumbnails featuring Swami Sarvapriyananda.
2. **Retriever R**: A process that retrieves relevant passages from the datastore.
3. **Chatbot C**: The core chatbot component that generates answers.
The diagram uses blue and green boxes to represent different stages of processing. Arrows indicate the direction of information flow.
### Detailed Analysis or ### Content Details
**1. Datastore D (Left Side):**
* The datastore is represented by a collection of video thumbnails. All thumbnails feature Swami Sarvapriyananda.
* Examples of video titles include:
* "MANDUKYA UPANISHAD CHAPTER 2 KARIKA-35"
* "VEDANTASARA of Sadananda PART 19: TEXTS 122-127"
* "Mundaka Upanishad PART 5 Mantras 1.1.8-9"
* "BHAGAVAD GITA Chapter 8 Verses 15-20"
* "QUESTIONS AND ANSWERS June 7th, 2020"
* "CONSCIOUSNESS AND SELF IN VEDANTA"
* "MODELS OF Consciousness IN INDIAN PHILOSOPHY"
* "ALL OF IT"
* "NONE OF IT"
* "SUNYAM THE VOID"
* "PURNAM THE FULL"
* "NO MIND"
**2. Retriever R (Middle Section):**
* **Hybrid Retrieval: Deep + Sparse**: This blue box represents the initial retrieval process. It takes input from the datastore.
* **Keyword extraction**: A blue box that is connected to the "Hybrid Retrieval" box.
* **Passage 1, Passage 2, ..., Passage k**: A stack of blue boxes representing the retrieved passages.
* **Context Refiner**: A blue box that refines the retrieved passages.
**3. Chatbot C (Right Side):**
* **Query (q)**: A green box representing the user's query. It receives input from the "Keyword extraction" box.
* **Prompt (p)**: A green box representing the prompt generated for the LLM. It receives input from the "Context Refiner" box and the "Query" box.
* **LLM**: A light green box representing the Large Language Model. It receives input from the "Prompt" box.
* **Answer (a)**: A green box representing the final answer generated by the chatbot. It is the output of the LLM.
### Key Observations
* The diagram illustrates a pipeline architecture where data flows sequentially from the datastore to the chatbot.
* The retriever uses a hybrid approach (Deep + Sparse) to retrieve relevant passages.
* Context refinement is used to improve the quality of the retrieved passages.
* The chatbot uses a Large Language Model (LLM) to generate answers.
### Interpretation
The diagram depicts a Retrieval-Augmented Generation (RAG) system for a chatbot. The datastore contains information, likely transcripts or summaries, from videos featuring Swami Sarvapriyananda. When a user poses a query, the system retrieves relevant passages from the datastore, refines the context, and uses an LLM to generate an answer based on the retrieved information. This approach allows the chatbot to provide informed and contextually relevant responses. The use of hybrid retrieval suggests an attempt to balance precision and recall in the retrieval process.